SS 04
Sven Eric Panitz
TFH Berlin
Version Jul 12, 2004
Dieses Skript entstand begleitend zur Vorlesung des SS 03 vollkommen neu. Es stellte somit eine Mitschrift der Vorlesung dar. Diese Version basiert auf der ersten Version erfährt jedoch im Laufe des Semesters einige Umstrukturierungen. Insbesondere das Kapitel über Klassenpfade und Jar-Dateien ist ins Skript Programmieren I[Pan03] gewandert.
Naturgemäß ist es in Aufbau und Qualität nicht mit einem Buch
vergleichbar. Flüchtigkeits- und Tippfehler werden sich im Eifer
des Gefechtes nicht vermeiden lassen und wahrscheinlich in nicht
geringem Maße auftreten. Ich bin natürlich stets dankbar, wenn
ich auf solche aufmerksam gemacht werde und diese korrigieren
kann.
Die Vorlesung setzt die Kerninhalte der Vorgängervorlesung
voraus[Pan03].
Der Quelltext dieses Skripts ist eine XML-Datei, die durch eine XQuery
in eine LATEX-Datei transformiert und für die schließlich eine
pdf-Datei und eine postscript-Datei
erzeugt wird.
Alle Beispielprogramme sind mit einem Skript aus dem Quelltext extrahiert und
übersetzt worden.
Contents
1 Frühe und späte Bindungen1.1 Wiederholung: Das Prinzip der späten Bindung
1.2 Keine späte Bindung für Felder
1.3 Keine Späte Bindung für überladene Methoden
2 Graphische Benutzeroberflächen und Graphiken
2.1 Graphische Benutzeroberflächen
2.1.1 Graphische Komponenten
2.1.2 Ereignisbehandlung
2.1.3 Setzen des Layouts
2.2 Exkurs: verschachtelte Klassen
2.2.1 Innere Klassen
2.2.2 Anonyme Klassen
2.2.3 Statische verschachtelte Klassen
2.3 Selbstdefinierte graphische Komponenten
2.3.1 Graphics Objekte
2.3.2 Dimensionen
2.3.3 Farben
2.3.4 Fonts und ihre Metrik
2.3.5 Erzeugen graphischer Dateien
2.3.6 Graphics2D
2.4 Weitere Komponente und Ereignisse
2.4.1 Mausereignisse
2.4.2 Fensterereignisse
2.4.3 Weitere Komponenten
2.5 Swing und Steuerfäden
2.5.1 Timer in Swing
2.5.2 SwingWorker für Steuerfäden in der Ereignisbehandlung
3 Abstrakte Datentypen
3.1 Bäume
3.1.1 Formale Spezifikation
3.1.2 Modellierung
3.1.3 Implementierung
3.2 Algorithmen auf Bäumen
3.2.1 Knotenanzahl
3.2.2 toString
3.2.3 Linearisieren
3.2.4 Eltern und Geschwister
3.2.5 Modifizierende Methoden
3.2.6 Bäume mit JTree graphisch darstellen
3.2.7 Bäume zeichnen
3.3 Binärbäume
3.3.1 Probleme der Klasse BinTree
3.3.2 Linearisieren binärer Bäume
3.4 Binäre Suchbäume
3.4.1 Suchen in Binärbäumen
3.4.2 Entartete Bäume
4 Formale Sprachen, Grammatiken, Parser
4.1 formale Sprachen
4.1.1 kontextfreie Grammatik
4.1.2 Erweiterte Backus-Naur-Form
4.2 Parser
4.2.1 Parsstrategien
4.3 Handgeschriebene Parser
4.3.1 Basisklassen der Parserbibliothek
4.3.2 Parser zum Erkennen von Token
4.3.3 Parser zum Bilden der Sequenz zweier Parser
4.3.4 Parser zum Bilden der Alternative zweier Parser
4.3.5 Parser zum Verändern des Ergebnisses
4.3.6 Beispiel: arithmetische Ausdrücke
4.3.7 Tokenizer
4.4 Parsergeneratoren
4.4.1 javacc
4.4.2 Parsen und moderne Programmierparadigmen
A Lösungen ausgewählter Aufgaben
A.1 Lösung der Punkteaufgabe zu Bäumen
A.1.1 leaves
A.1.2 show
A.1.3 contains
A.1.4 maxDepth
A.1.5 getPath
A.1.6 iterator
A.1.7 sameStructure
A.1.8 equals
B Hilfklasssen zu Swing
C Beispielaufgaben
D Referate
D.1 JNI: Javas Schnittstelle zu C
D.2 Java 2D Grafik
D.3 Java 3D Grafik
D.4 Java und Netzwerk
D.5 Java und Datenbanken
E Gesammelte Aufgaben
Einführung
Ziel der Vorlesung
Mit den Grundtechniken der Programmierung am Beispiel von Java wurde
in der Vorgängervorlesung vertraut gemacht. Jetzt ist es an der Zeit,
das Gelernte anzuwenden und gängige Techniken und Muster der
Programmierung zu lernen. Im Prinzip wird kein neues Javakonstrukt
kennengelernt werden1, sondern mit vorhandenen Bibliotheken vetraut
gemacht. Am Ende der Vorlesung sollte im besten Fall erreicht sein,
daß jeder Teilnehmer sich in der Lage sieht, selbstständig
fremde Bibliotheken zu verwenden und eigene Bibliotheken zu
entwerfen.
Eine große Bibliothek, mit der insbesondere in dieser Vorlesung vertraut
gemacht werden soll, ist Javas Standardbibliothek für graphische
Benutzeroberflächen: Swing.
Chapter 1
Chapter 1
Frühe und späte Bindungen
1.1 Wiederholung: Das Prinzip der späten Bindung
Methoden aus Klassen können in einer Unterklasse überschrieben werden. Damit
gibt es mehrere Methodendefinitionen mit gleichen Namen und gleicher
Signatur. Wenn das Programm kompiliert wird, wird in den erzeugten Code nicht
hineingeschrieben, welche dieser zwei gleich heißenden Methodendefinitionen
ausgeführt werden soll. Erst zur Ausführungszeit wird das in Frage kommende
Objekt gefragt, ob es eine eigene Definition für diese Methode hat, und dann
diese genommen. Der Aufrufer muß dabei noch nicht einmal wissen, um was für
eine spezielle Unterklasse es sich in diesem Fall handelt.
Wem obiger Absatz zu abstrakt klingt, betrachte folgendes simple Beispiel.
Beispiel:
Wir sehen zunächst eine Schnittstelle vor. Dieses wäre zur Verdeutlichung der späten Bindung nicht unbedingt notwendig. Objekte, die diese Schnittstelle implementieren, sollen eine Methode getDescription enthalten.
Descriptable
package name.panitz.lateBinding;
public interface Descriptable{
String getDescription();
}
Jetzt können wir eine Klasse schreiben, die diese Schnittstelle implementiert.
Upper
package name.panitz.lateBinding;
public class Upper implements Descriptable{
public String getDescription(){return "Upper";}
}
Von dieser Klasse schreiben wir eine Unterklasse, die eine eigene neue
Implementierung der Methode getDescription enthält.
Lower
package name.panitz.lateBinding;
public class Lower extends Upper{
public String getDescription(){return "Lower";}
Jetzt erzeugen wir einmal von beiden Klassen Objekte und speichern sie
zunächst in Variablen des Typs Upper. Obwohl wir den Variablen selbst
nicht mehr ansehen können, ob in ihnen Objekte des Typs Upper oder Lower gespeichert sind, wird jeweils die eigene Methode des
Objektes ausgeführt. Das gleiche läßt sich beobachten, wenn die Objekte in
einer Variablen des Schnittstellentyps Descriptable gespeichert sind.
Lower
public static void main(String[] _){
Upper up = new Upper();
Upper lo = new Lower();
System.out.println(up.getDescription());
System.out.println(lo.getDescription());
Descriptable des = up;
System.out.println(des.getDescription());
des = lo;
System.out.println(des.getDescription());
}
}
Wir können folgende Ausgabe des Testprogramms beobachten:
sep@linux:~/fh/prog2/examples> java -classpath classes/ name.panitz.lateBinding.Lower Upper Lower Upper Lower sep@linux:~/fh/prog2/examples>
1.2 Keine späte Bindung für Felder
Wir haben in der
Vorlesung Programmieren I nicht unerwähnt
gelassen, daß das Prinzip der späten Bindung nur für Methoden und
nicht für Felder gilt. Damit sind Felder in Java in gewisser Weise
nur Eigenschaften zweiter Klasse; ihnen steht ein fundamentales Konzept
für Methoden nicht zur Verfügung. Diese Eigenschaft kann eine
Stolperfalle für Programmierer sein und ist oft an Java kritisiert
worden. Um uns die entsprechenden Effekte zu illustrieren schreiben
wir eine kleine Klasse, die uns eine Ente modellieren soll:
Ente
package name.panitz.lateBinding;
class Ente {
int beine = 2;
int getBeine(){return beine;}
int getWirklicheBeine(){return beine;}
}
In der Klasse ist in einem Feld gespeichert wieviel Beine eine Ente
hat. Zwei Methoden sind reine get-Methoden, indem sie nur den
Wert des Feldes beine auslesen.
Als nächstes schreiben wir eine Unterklasse der
Klasse Ente. Diese Klasse soll besondere Enten beschreiben, deren
Schicksal es ist, nur noch ein Bein zu haben. Wir überschreiben das
Feld beine mit dem neuen Wert 1. Ebenso
überschreiben wir die Methode getWirklicheBeine, allerdings
mit der identischen Implementierung aus der Oberklasse.
LahmeEnte
package name.panitz.lateBinding;
class LahmeEnte extends Ente {
int beine = 1;
int getWirklicheBeine(){return beine;}
}
Jetzt können wir versuchen alle drei Eigenschaften
auszuprobieren. Hierzu legen wir von beiden Klassen jeweils ein
Objekt an und geben für die entsprechenden Objekte die drei
Eigenschatfen auf dem Bildschirm aus. Dabei erzeugen wir ein Objekt
vom Typ LahmeEnte und geben die Eigenschaften einmal aus,
indem wir das Objekt einmal von einem Feld des Typs Ente und
einmal von einem Feld des Typs LahmeEnte referenzieren.
EntenTest
package name.panitz.lateBinding;
class EntenTest {
public static void main(String [] args){
Ente ente1 = new Ente();
LahmeEnte ente2 = new LahmeEnte();
Ente ente3 = ente2;
System.out.println("Ente ente1 = new Ente()");
System.out.println("beine: "+ente1.beine);
System.out.println("getBeine(): "+ente1.getBeine());
System.out.println(
"getWirklicheBeine(): "+ente1.getWirklicheBeine());
System.out.println(
"\nLahmeEnte ente2 = new LahmeEnte()");
System.out.println("beine: "+ente2.beine);
System.out.println("getBeine(): "+ente2.getBeine());
System.out.println(
"getWirklicheBeine(): "+ente2.getWirklicheBeine());
System.out.println("\nEnte ente3 = new LahmeEnte()");
System.out.println("beine: "+ente3.beine);
System.out.println("getBeine(): "+ente3.getBeine());
System.out.println(
"getWirklicheBeine(): "+ente3.getWirklicheBeine());
}
}
Starten wir das Programm, so stellen wir ein paar unerwartete Effekte fest:
sep@swe10:~/fh/prog2/beispiele> java name.panitz.lateBinding.EntenTest Ente ente1 = new Ente() beine: 2 getBeine(): 2 getWirklicheBeine(): 2 LahmeEnte ente2 = new LahmeEnte() beine: 1 getBeine(): 2 getWirklicheBeine(): 1 Ente ente3 = ente2 beine: 2 getBeine(): 2 getWirklicheBeine(): 1 sep@swe10:~/fh/prog2/beispiele>
Für das Objekt ente1 vom Typ Ente haben wir noch die
erwarteten Ergebnisse. 2 Beine, egal über welche Methode wir darauf
zugreifen. Für das Objekt ente2 haben wir zwei zunächst
überraschende Ergebnisse.
Während beine und getWirklicheBeine() in der
Betrachtung als Feld vom Typ LahmeEnte jeweils die
Zahl 1 als Ergebnis liefern, so liefert die
Methode getBeine() den Wert 2. Dieses liegt daran,
daß wir diese Methode nicht überschrieben haben. Sie wird aus der
Klasse Ente geerbt. Diese greift auf das
Feld beine zu. Da für Felder das Prinzip der späten Bindung
nicht gilt, greift sie auf das Feld beine der
Klasse Ente und nicht der Klasse LahmeEnte zu.
Daher erhalten wir den Wert aus der Klasse Ente.
Das zweite überraschende Ergebnis ist, wenn wir das Objekt der
Klasse LahmeEnte von einem Feld der
Klasse Ente betrachten. Dann bekommen wir für das
Feld beine plötzlich für dasselbe Objekt einen anderen
Wert (die 2) ausgegeben. Für dasselbe Objekt plötzlich einen
anderen Wert zu bekommen, widerspricht unserer Intuition von
Objekten.
Auch hier ist die fehlende späte Bindung für Felder dran
ursächlich. Anders als bei Methodenaufrufen, in denen wir sagen, das
Objekt soll selbst seine eigene Methode mit dem entsprechenden Namen
ausführen, sagt der Aufrufer aus welcher Klasse er das Feld haben
möchte. Bei Feldern ist nicht der Typ, mit dem das Objekt einst erzeugt
wurde, sondern der Typ, unter dem es betrachtet, mit dem es
referenziert wird, relevant.
Dieses läßt sich besonders durch eine Typzusicherung illustrieren:
EntenTest2
package name.panitz.lateBinding;
class EntenTest2 {
public static void main(String [] args){
Ente ente = new LahmeEnte();
System.out.println( ente .beine);
System.out.println(((LahmeEnte)ente).beine);
}
}
Die Ausgabe dieses Tests ist:
sep@swe10:~/fh/prog2/beispiele> java name.panitz.lateBinding.EntenTest2 2 1 sep@swe10:~/fh/prog2/beispiele>
Wie man sieht sind überschriebene Felder mit Vorsicht zu
genießen. Deshalb ist es zu empfehlen Felder nicht zu überschreiben.
Besonders sicher fährt man, wenn man Felder privat macht und nur über
get- und set-Methoden auf Felder zugreift.
1.3 Keine Späte Bindung für überladene Methoden
Es gibt noch eine zweite Art und Weise verschiedene Funktionsdefinitionen für
eine Methode zu haben. Statt in verschiedenen Klassen eine Funktion zu
schreiben, kann man auch in einer Klasse eine Methode für verschiedene
Argumenttypen überladen. Um dieses zu Demonstrieren, schreiben wir eine kleine
Klassenhierarchie aus drei Klassen:
Up
package name.panitz.overload;
public class Up{}
Für diese Oberklasse schreiben wir zwei Unterklassen.
Down1
package name.panitz.overload;
public class Down1 extends Up{}
Down2
package name.panitz.overload;
public class Down2 extends Up{}
Jetzt überladen wir eine Methode getDescription für Argumente dieser
drei Klassen
GetDescription
package name.panitz.overload;
public class GetDescription {
public String getDescription(Up _){return "Up";}
public String getDescription(Down1 _){return "Down1";}
public String getDescription(Down2 _){return "Down2";}
Zum Testen wenden wir die Methode auf Objekte dieser Klassen an. Dabei
zunächst über Variablen, die jeweils genau den Typ des Objekts und nicht einer
Oberklasse haben. Dann speichern wir die Objekte in der Variablen des
gemeinsamen Obertyps Up. Und schließlich noch, indem wir zuvor wieder
eine Typzusicherung auf den eigentlichen Objekttyp vornehmen.
GetDescription
public static void main(String [] _){
GetDescription g = new GetDescription();
Up up = new Up();
Down1 down1 = new Down1();
Down2 down2 = new Down2();
System.out.println(g.getDescription(up));
System.out.println(g.getDescription(down1));
System.out.println(g.getDescription(down2));
up = down1;
System.out.println(g.getDescription(up));
up = down2;
System.out.println(g.getDescription(up));
System.out.println(g.getDescription((Down2)up));
}
}
An der Ausgabe kann man sich davon überzeugen, daß das Objekt nicht gefragt
wird, von welchen Typ es eigentlich ist. Es wird jeweils die
Methodendefinition genommen, die auf den Typ der Variablen passt.
sep@linux:~/fh/prog2/examples> java -classpath classes/ name.panitz.overload.GetDescription Up Down1 Down2 Up Up Down2 sep@linux:~/fh/prog2/examples>
Späte Bindung findet also für überladene Methoden nicht statt. Der Übersetzer
generiert fest den Methodenaufruf, für genau den Typ, den der statische
Typchecker für das Argument festgestellt hat.
Chapter 2
Chapter 2
Graphische Benutzeroberflächen und Graphiken
Die meisten Programme auf heutigen Rechnersystemen haben eine
graphische Benutzeroberfläche (GUI)2.
Java stellt Klassen zur
Verfügung, mit denen graphische Objekte erzeugt und in ihrem Verhalten
instrumentalisiert werden können. Leider gibt es
historisch gewachsen zwei Pakete in Java mit Klassen zur
GUI-Programmierung. Die beiden Pakete überschneiden sich in der
Funktionalität.
- java.awt: Dieses ist das ältere Paket zur GUI-Programmierung. Es enthält Klassen für viele graphische Objekte (z.B. eine Klasse Button) und Unterpakete, zur Programmierung der Funktionalität der einzelnen Komponenten.
- javax.swing: Dieses neuere Paket ist noch universeller und platformunabhängiger als das java.awt-Paket. Auch hier finden sich Klassen für unterschiedliche GUI-Komponenten. Sie entsprechen den Klassen aus dem Paket java.awt. Die Klassen haben oft den gleichen Klassennamen wie in java.awt jedoch mit einem J vorangestellt. So gib es z.B. eine Klasse JButton.
Ein fundamentaler Unterschied dieser beiden Pakete besteht in ihrer Behandlung
von Steuerfäden. Während das awt-Paket sicher in Bezug auf
Steuerfäden ist, können im swing-Paket Steuerfäden nicht ohne
zusätzlihe Absicherung benutzt werden.
Zu allen Unglück sind die beiden Pakete nicht ganz unabhängig. Man ist zwar
angehalten, sofern man sich für eine Implementierung seines Guis mit
den Paket javax.swing entschieden hat, nur die graphischen
Komponenten aus diesem Paket zu benutzen; die Klassen leiten aber von
Klassen des Pakets java.awt ab. Hinzu kommt, daß die
Ereignissklassen, die die Funktionalität graphischer Objekte
bestimmen, nur in java.awt existieren und nicht noch einmal
für javax.swing extra umgesetzt wurden.
Sind Sie verwirrt. Sie werden es hoffentlich nicht mehr sein, nachdem
Sie die Beispiele dieses Kapitels durchgespielt haben.
2.1 Graphische Benutzeroberflächen
Zur Programmierung eines GUIs bedarf es graphischer Objekte, einer
Möglichkeit, graphische Objekte zu gruppieren, und schließlich eine
Möglichkeit zu bestimmen, wie die Objekte auf bestimmte Ereignisse
reagieren (z.B. was passiert, wenn ein Knopf gedrückt
wird). Java kennt für diese Aufgaben jeweils eigene Klassen:
- Komponenten
- Ereignisbehandlung
- Layoutstuerung
In den folgenden Abschnitten, werden wir an ausgewählten Beispielen
Klassen für diese drei wichtigen Schritte der GUI-Programmierung
kennenlernen.
2.1.1 Graphische Komponenten
Javas swing-Paket kennt drei Arten von Komponenten.
- Top-Level Komponenten
- Zwischenkomponenten
- Atomare Komponenten
Leider spiegelt sich diese Unterscheidung nicht in der
Ableitungshierarchie wider. Alle Komponenten leiten schließlich von
der Klasse java.awt.Component ab. Es gibt keine
Schnittmengen, die Beschreiben, daß bestimmte Komponenten atomar oder
top-level sind.
Komponenten können Unterkomponenten enthalten; ein Fenster kann
z.B. verschiedene Knöpfe und Textflächen als
Unterkomponenten enthalten.
Top-Level Komponenten
Eine top-level Komponenten ist ein GUI-Objekt, das weitere graphische
Objekte enthalten kann, selbst aber kein graphisches Objekt hat, in
dem es enthalten ist. Somit sind top-level Komponenten in der Regel
Fenster, die weitere Komponenten als Fensterinhalt haben.
Swing top-level Komponenten sind Fenster und
Dialogfenster. Hierfür stellt Swing entsprechende Klassen zur
Verfügung: JFrame, JDialog
Eine weitere top-level Komponente steht für Applets zur
Verfügung: JApplet.
Graphische Komponenten haben Konstruktoren, mit denen sie erzeugt
werden. Für die Klasse JFrame existiert ein parameterloser
Konstruktor.
Beispiel:
Das minimalste GUI-Programm ist wahrscheinlich folgendes Programm, das ein Fensterobjekt erzeugt und dieses sichtbar macht.
Window1
package name.panitz.simpleGui;
import javax.swing.*;
public class Window1{
public static void main(String [] _){
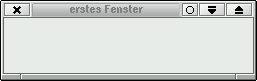
new JFrame("erstes Fenster").setVisible(true);
}
}
Dieses Programm erzeugt ein leeres Fenster und gibt das auf dem
Bildschirm aus.
Der Fenstertitel kann als Argument dem Konstruktor der
Klasse JFrame als String übergeben werden.
Die optische Ausprägung des Fensters kann vom Betriebssystem
abhängen. In Abbildung 2.1 ist dieses Fenster
beispielhaft in einer Suse Linux Umgebung mit KDE zu bewundern.
Zwischenkomponenten
Graphische Zwischenkomponenten haben primär die Aufgabe andere
Komponenten als Unterkomponenten zu haben und diese in einer
bestimmten Weise anzuordnen. Zwischenkomponenten haben oft keine
eigene visuelle Ausprägung. Sie sind dann unsichtbare Komponenten, die
als Behälter weiterer Komponenten dienen.
Die gebräuchlichste Zwischenkomponenten ist von der
Klasse JPanel. Weitere Zwischenkomponenten sindJScrollPane und JTabbedPane. Diese haben auch eine
eigene visuelle Ausprägung.
Die Objekte der Klasse JFrame enthalten bereits eine
Zwischenkomponente. Diese kann mit der
Methode getContentPane erhalten werden, um dieser
Zwischenkomponenten schließlich weitere Unterkomponenten, den Inhalt
des Fensters, hinzufügen zu können.
Atomare Komponenten
Die atomaren Komponenten sind schließlich Komponenten, die ein
konkretes graphisches Objekt darstellen, das keine weiteren
Unterkomponenten enthalten kann.
Solche Komponenten sind z.B.
JButton, JTextField, JTable und JComBox.
JButton, JTextField, JTable und JComBox.
Diese Komponenten lassen sich über ihre Konstruktoren instanziieren,
um sie dann einer Zwischenkomponenten über deren
Methode add als Unterkomponente hinzuzufügen.
Sind alle gewünschten graphischen Objekte einer Zwischenkomponente
hinzugefügt worden, so kann auf der zugehörigen top-level Komponenten
die Methode pack aufgerufen wurden. Diese berechnet die
notwendige Größe und das Layout des Fensters, welches schließlich
sichtbar gemacht wird.
In der Regel wird man nicht die Fenster des Programms nacheinander in
der Hauptmethode definieren, sondern die gebrauchten Fenster werden
als eigene Objekte definiert. Hierzu leitet man eine spezifische
Fensterklasse von der Klasse JFrame ab und fügt bereits im
Konstruktor die entsprechenden Unterkomponenten hinzu.
Beispiel:
Das folgende Programm erzeugt ein Fenster mit einer Textfläche.
JT
package name.panitz.simpleGui;
import javax.swing.*;
class JT {
public static void main(String [] _){
JFrame frame = new JFrame();
JTextArea textArea = new JTextArea();
textArea.setText("hallo da draußen");
frame.getContentPane().add(textArea);
frame.pack();
frame.setVisible(true);
}
}
Das Programm erzeugt das folgende Fenster:

Beispiel:
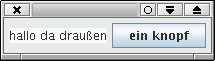
Die folgende Klasse definiert ein Fenster, das einen Knopf und eine Textfläche enthält. In der Hauptmethode wird das Objekt instanziiert:
JTB
package name.panitz.simpleGui;
import javax.swing.*;
class JTB extends JFrame {
JPanel pane = new JPanel();
JTextArea textArea = new JTextArea();
JButton button = new JButton("ein Knopf");
public JTB(){
textArea.setText("hallo da draußen");
pane.add(textArea);
pane.add(button);
getContentPane().add(pane);
pack();
setVisible(true);
}
public static void main(String [] _){
new JTB();
}
}
Das Programm erzeugt folgendes Fenster:
2.1.2 Ereignisbehandlung
Wir haben es bisher schon geschafft ein Fenster zu definieren, in dem mehrere
graphische Komponenten dargestellt werden. Für ein funktionierendes GUI ist es
nun notwendig, für einzelne Komponenten eine Funktionalität zu
definieren. Hierzu kennt Swing das Konzept der Ereignisbehandlung. Graphischen
Komponenten kann ein Ereignisbehandlungsobjekt angehänt werden. Objekte zur
Ereignisbehandlung müssen dabei bestimmte Schnittstellen implementieren, die
sogenannten Listener.
Ereignisarten gibt es eine ganze Reihe auf den unterschiedlichsten
graphischen Komponenten: ein Knöpf kann gedrückt werden, ein Fenster
minimiert, mit der Maus auf eine Komponente gezeigt werden, ein Menupunkt
gewählt werden etc. Für die unterschiedlichen Ereignisarten gibt es
unterschiedliche Schnittstellen, die beschreiben, wie auf solche Ereignisse
reagiert werden soll. Die Schnittstellen für Ereignisse befinden sich im
Paket: java.awt.event.*.
Beispiel:
Als erstes Beispiel für eine Ereignisbehandlung betrachten wir die vielleicht elementarste Art eines Ereignisses: ein Knopf wird gedrückt. Hierzu gibt es die elementare Ereignisbehandlungsschnittstelle: java.awt.event.ActionListener. Diese Schnittstelle enthält nur eine Methode: actionPerformed
Wir implementieren diese Schnittstelle. Unsere Klasse zur Ereignisbehandlung
bekommt dabei ein Textfeld übergeben. Intern enthalte die
Klasse einen Zähler. Wann immer das Ereignis eintritt, soll der Zähler um eins
erhöht werden und das neue Ergebnis des Zählers im Textfeld angezeigt werden.
CounterListener
package name.panitz.simpleGui;
import java.awt.event.*;
import javax.swing.*;
public class CounterListener implements ActionListener{
private final JTextArea textArea;
private int counter = 0;
public CounterListener(JTextArea ta){textArea=ta;}
public void actionPerformed(ActionEvent _){
counter = counter+1;
textArea.setText(counter+"");
}
}
Jetzt können wir eine Unterklasse unserer letzten kleinen
Gui-Klasse JTB schreiben, in der diese Ereignisbehandlung dem Knopf
hinzugefügt wird. Hierzu gibt es für Knöpfe die
Methode addActionListener.
Counter
package name.panitz.simpleGui;
import javax.swing.*;
class Counter extends JTB {
public Counter(){
super();
button.addActionListener(new CounterListener(textArea));
}
public static void main(String [] _){new Counter();}
}
Und tatsächlich, wenn wir dieses Programm starten, so bewirkt, daß ein Drücken
des Knopfes mit der Maus bewirkt, daß im Textfeld angezeigt wird, wie oft
bisher der Knopf gedrückt wurde.
Aufgabe 1
Die Methode actionPerformed der
Schnittstelle ActionListener bekommt ein Objekt der
Klasse ActionEvent übergeben. In dieser gibt es eine
Methode getWhen, die den Zeitpunkt, zu dem das Ereignis aufgetreten
ist als eine Zahl kodiert zurückgibt. Mit dieser Zahl können Sie die
Klasse java.util.Date instanziieren, um ein Objekt zu bekommen, das
Datum und Uhrzeit enthält.
Schreiben Sie jetzt eine Unterklasse von JTB, so daß beim Drücken des
Knopfes, jetzt die aktuelle Uhrzeit im Textfeld erscheint.
Aufgabe 2
Schreiben Sie eine kleine Guianwendung mit einer Textfläche und drei
Knöpfen, die einen erweiterten Zähler darstellt:
- einen Knopf zum Erhöhen eines Zählers.
- einen Knopf zum Verringern des Zählers um 1.
- einen Knopf zum Zurücksetzen des Zählers auf 0.
2.1.3 Setzen des Layouts
Bisher haben wir Unterkomponenten weitere Komponenten mit der
Methode add hinzugefügt, ohne uns Gedanken über die
Plazierung der Komponenten zu machen. Wir haben einfach auf das
Standardverhalten zur Plazierung von Komponenten vertraut.
Ob die Komponenten schließlich nebeneinander, übereinander oder irgendwie
anders Gruppiert im Fenster erschienen, haben wir nicht spezifiziert.
Um das Layout von graphischen Komponenten zu steuern, steht das Konzept
der sogenannten Layout-Manager zur Verfügung. Ein
Layout-Manager ist ein Objekt, das einer Komponente hinzugefügt
wird. Der Layout-Manager steuert dann, in welcher Weise die
Unterkomponenten gruppiert werden.
LayoutManager ist eine Schnittstelle. Es gibt mehrere
Implementierungen dieser Schnittstelle. Wir werden in den nächsten
Abschnitten drei davon kennenlernen. Es steht einem natürlich frei,
eigene Layout-Manager durch Implementierung dieser Schnittstelle zu
schreiben. Es wird aber davon abgeraten, weil dieses notorisch
schwierig ist und die in Java bereits vorhandenen Layout-Manager
bereits sehr mächtig und ausdrucksstark sind.
Zum Hinzufügen eines Layout-Manager gibt es die Methode setLayout.
Flow Layout
Der vielleicht einfachste Layout-Manager nennt
sich FlowLayout. Hier werden die Unterkomponenten einfach der
Reihe nach in einer Zeile angeordnet. Erst wenn das Fenster zu schmal
hierzu ist, werden weitere Komponenten in eine neue Zeile gruppiert.
Beispiel:
Die folgende Klasse definiert ein Fenster, dessen Layout über ein Objekt der Klasse FlowLayout gesteuert wird. Dem Fenster werden fünf Knöpfe hinzugefügt:
FlowLayoutTest
package name.panitz.gui.layoutTest;
import java.awt.*;
import javax.swing.*;
class FlowLayoutTest extends JFrame {
public FlowLayoutTest(){
Container pane = getContentPane();
pane.setLayout(new FlowLayout());
pane.add(new JButton("eins"));
pane.add(new JButton("zwei"));
pane.add(new JButton("drei (ein langer Knopf)"));
pane.add(new JButton("vier"));
pane.add(new JButton("fuenf"));
pack();
setVisible(true);
}
public static void main(String [] _){new FlowLayoutTest();}
}
Das Fenster hat folgende optische Ausprägung.

Verändert man mit der Maus die Fenstergröße, macht es
z.B. schmal und hoch, so werden die Knöpfe nicht mehr
nebeneinander sonder übereinander angeordnet.
Border Layout
Die Klasse BorderLayout definiert einen Layout Manager, der
fünf feste Positionen kennt: eine Zentralposition, und jeweils
links/rechts und oberhalb/unterhalb der Zentralposition eine Position
für Unterkomponenten. Die Methode add kann in diesem Layout
auch noch mit einem zweitem Argument aufgerufen werden, das eine
dieser fünf Positionen angibt. Hierzu bedient man sich der konstanten
Felder der Klasse BorderLayout.
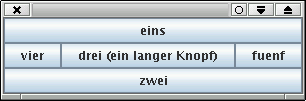
Beispiel:
In dieser Klasse wird die Klasse BorderLayout zur Steuerung des Layoout benutzt. Die fünf Knöpfe werden an jeweils eine der fünf Positionen hinzugefügt:
BorderLayoutTest
package name.panitz.gui.layoutTest;
import java.awt.*;
import javax.swing.*;
class BorderLayoutTest extends JFrame {
public BorderLayoutTest(){
Container pane = getContentPane();
pane.setLayout(new BorderLayout());
pane.add(new JButton("eins"),BorderLayout.NORTH);
pane.add(new JButton("zwei"),BorderLayout.SOUTH);
pane.add(new JButton("drei (ein langer Knopf)")
,BorderLayout.CENTER);
pane.add(new JButton("vier"),BorderLayout.WEST);
pane.add(new JButton("fuenf"),BorderLayout.EAST);
pack();
setVisible(true);
}
public static void main(String [] _){new BorderLayoutTest();}
}
Die Klasse erzeugt das folgende Fenster.
Das Layout ändert sich nicht, wenn man mit der Maus die Größe und das
Format des Fensters verändert.
Grid Layout
Die Klasse GridLayout ordnet die Unterkomponenten
tabellarisch an. Jede Komponente wird dabei gleich groß
ausgerichtet. Die Größe richtet sich also nach dem größten Element.
Beispiel:
Folgende Klasse benutzt ein Grid-Layout mit zwei Zeilen zu je drei Spalten.
GridLayoutTest
package name.panitz.gui.layoutTest;
import java.awt.*;
import javax.swing.*;
class GridLayoutTest extends JFrame {
public GridLayoutTest(){
Container pane = getContentPane();
pane.setLayout(new GridLayout(2,3));
pane.add(new JButton("eins"));
pane.add(new JButton("zwei"));
pane.add(new JButton("drei (ein langer Knopf)"));
pane.add(new JButton("vier"));
pane.add(new JButton("fünf"));
pack();
setVisible(true);
}
public static void main(String [] _){new GridLayoutTest();}
}
Folgendes Fensters wird durch dieses Programm geöffnet.

Auch hier ändert sich das Layout nicht, wenn man mit der Maus die
Größe und das
Format des Fensters verändert.
2.2 Exkurs: verschachtelte Klassen
Bisher haben wir gelernt, daß jede Java Quelltextdatei genau eine Klasse
enthält und Klassen Eigenschaften in Form von Feldern und Methoden
enthalten. In den ersten GUI-Beispielen und Aufgaben haben wir schon gesehen,
daß es insbesondere für die Ereignisbehandlung oft zu sehr kleinen Klassen
kommt, die lediglich für eine ganz spezielle Funktionalität innerhalb einer
GUI-Klasse benötigt werden. Um in solchen Situationen den Code etwas
struktuierter zu schreiben, so daß ein Ereignisbehandler direkt im Quelltext
bei dem GUI-Objekt zu finden ist, gibt es in Java die Möglichkeit, innerhalb
einer Klasse ein interne Klasse zu schreiben. Hierbei spricht man von
verschachtelten Klassen. Verschachtelte Klassen können statisch sein, oder als
nicht-statische Eigenschaft an konkrete Objekte gebunden sein. In diesem Fall
heißen sie: innere Klassen. Tatsächlich können verschachtelte
überall im Code auftauchen: sie können auf obere Ebene parallel zu Feldern und
Methoden in einer Klasse definiert werden, aber auch an beliebiger Stelle
innerhalb eines Methodenrumpfes.
2.2.1 Innere Klassen
Eine innere Klasse wird gechrieben wie jede andere Klasse auch, nur daß sie
eben im Rumpf einer äußeren Klasse auftauchen kann. Die innere Klasse hat das
Privilig auf die Eigenschaften der äußeren Klasse zuzugreifen, sogar auf die
als privat markierten Eigenschaften. Das Attribut privat soll lediglich
verhindern, daß eine Eigenschaft von außerhalb der Klasse benutzt wird. Innere
Klasse befinden sich aber innerhalb der Klasse.
Beispiel:
Unser erstes GUI mit einer Funktionalität läßt sich jetzt mit Hilfe einer inneren Klasse in einer Datei schreiben. Das Feld counter, das wir in der vorherigen Implementierung als privates Feld der Klass CounterListener definiert hatten, haben wir hier als Feld der GUI-Klasse modelliert. Trotzdem kann die Klasse CounterListener weiterhin darauf zugreifen. Ebenso brauch die Textfläche nicht der Klasse CounterListener im Konstruktor übergeben werden. Als innere Klasse kann in CounterListener auf dieses Feld der äußeren Klasse zugegriffen werden.
InnerCounter
package name.panitz.simpleGui;
import javax.swing.*;
import java.awt.event.*;
class InnerCounter extends JTB {
private int counter = 0;
class CounterListener implements ActionListener{
public void actionPerformed(ActionEvent _){
counter = counter+1;
textArea.setText(counter+"");
}
}
public InnerCounter(){
button.addActionListener(new CounterListener());
}
public static void main(String [] _){new InnerCounter();}
}
Tatsächlich ist die Implementierung kürzer und etwas übersichtlicher
geworden.
Beim Übersetzen einer Klasse mit inneren Klassen, erzeugt der Javaübersetzer
für jede innere Klasse eine eigene Klassendatei:
sep@linux:~/fh/prog2/examples/classes/name/panitz/simpleGui> ll *.class -rw-r--r-- 1 sep users 1082 2004-03-29 11:36 InnerCounter$CounterListener.class -rw-r--r-- 1 sep users 892 2004-03-29 11:36 InnerCounter.class
Der Javaübersetzer schreibt intern den Code um in eine Menge von Klassen ohne
innere Klassendefinition und erzeugt für diese den entsprechenden Code.
Für die innere Klasse generiert der Javaübersetzer einen Namen, der sich aus
äußeren und inneren Klassenamen durch ein Dollarzeichen getrennt zusammensetzt.
Aufgabe 3
Schreiben Sie Ihr Programm eines Zählers mit drei Knöpfen jetzt so, daß sie
innere Klassen benutzen.
2.2.2 Anonyme Klassen
Im letzten Abschnitt hatten wir bereits das Beispiel einer inneren Klasse, für
die wir genau einmal ein Objekt erzeugen. In diesem Fall wäre es eigentlich
unnötig für eine solche Klasse einen Namen zu erfinden, wenn man an genau
dieser einen Stelle, an der das Objekt erzeugt wird, die entsprechende Klasse
spezifizieren könnte. Genau hierzu dienen anonyme Klassen in Java. Sie
ermöglichen, Klassen ohne Namen zu instanziieren. Hierzu ist nach dem
Schlüsselwort new anzugeben, von
welcher Oberklasse namenlose Klasse ableiten soll, oder welche Schnittstelle
mit der namenlosen Klasse implementiert werden soll. Dann folgt nach dem
leeren Klammerpaar für dem Konstruktoraufruf in geschweiften Klammern der
Rumpf der namenlosen Klasse.
Beispiel:
Wir schreiben ein drittes Mal die Klasse Counter. Diesmal wird statt der nur einmal instanziierten inneren Klasse eine anonyme Implementierung der Schnittstelle ActionListener Instanziiert.
AnonymousCounter
package name.panitz.simpleGui;
import javax.swing.*;
import java.awt.event.*;
class AnonymousCounter extends JTB {
private int counter = 0;
public AnonymousCounter(){
button.addActionListener(
new ActionListener(){
public void actionPerformed(ActionEvent _){
counter = counter+1;
textArea.setText(counter+"");
}
});
}
public static void main(String [] _){new AnonymousCounter();}
}
Auch für anonyme Klassen generiert der Javaübersetzer eigene
Klassendateien. Mangels eines Names, numeriert der Javaübersetzer hierbei die
inneren Klassen einfach durch.
sep@linux:~/fh/prog2/examples/classes/name/panitz/simpleGui> ll *.class -rw-r--r-- 1 sep users 1106 2004-03-29 11:59 AnonymousCounter$1.class -rw-r--r-- 1 sep users 887 2004-03-29 11:59 AnonymousCounter.class sep@linux:~/fh/prog2/examples/classes/name/panitz/simpleGui>
2.2.3 Statische verschachtelte Klassen
Selten benutzt gibt es auch statische verschachtelte Klassen. Diese können
entsprechend auch nur auf statische Eigenschaften der äußeren Klasse
zugreifen.
2.3 Selbstdefinierte graphische Komponenten
Bisher graphische Komponenten unter Verwendung der fertigen
GUI-Komponente aus der Swing-Bibliothek zusammengesetzt.
Oft will man graphische Komponenten schreiben, für die
es keine fertige
GUI-Komponente in der Swing-Bibliothek gibt. Wir müssen wir eine
entsprechende Komponente selbst schreiben.
2.3.1 Graphics Objekte
Um eine eigene GUI-Komponente zu schreiben, schreibt man eine Klasse,
die von der GUI-Klasse ableitet. Dieses haben wir
bereits in den letzten Beispielen getan, indem wir von der
Klasse JFrame abgelitten haben. Die dort geschriebenen
Unterklassen der Klasse JFrame zeichneten sich dadurch aus,
daß sie eine Menge von graphischen Objekten (Knöpfe,
Textfelder...) in einer Komponente zusammengefasst haben. In
diesem Abschnitt werden wir eine neue Komponente definieren, die keine
der bestehenden fertigen Komponenten benutzt, sondern selbst alles
zeichnet, was zu ihrer Darstellung notwendig ist.
Hierzu betrachten wir eine der entscheidenen Methoden der
Klasse JComponent, die
Methode paintComponent.
In
dieser Methode wird festgelegt, was zu zeichnen ist, wenn die
graphische Komponente darzustellen ist. Die
Methode paintComponent hat folgende Signatur:
public void paintComponent(java.awt.Graphics g)
Java ruft diese Methode immer auf, wenn die graphische Komponente aus
irgendeinen Grund zu zeichnen ist. Dabei bekommt die Methode das
Objekt übergeben, auf dem gezeichnet wird. Dieses Objekt ist vom
Typ java.awt.Graphics. Es stellt ein zweidimensionales
Koordinatensystem dar, in dem zweidimensionale Graphiken gezeichnet
werden können. Der Nullpunkt dieses Koordinatensystems ist oben links
und nicht unten links, wie wir es vielleicht aus der Mathematik
erwartet hätten.
In der Klasse Graphics sind eine Reihe von Methoden
definiert, die es erlauben graphische Objekte zu zeichnen. Es gibt
Methoden zum Zeichnen von Geraden, Vierecken, Ovalen, beliebigen
Polygonzügen, Texten etc.
Wollen wir eine eigene graphische Komponente definieren, so können wir
die Methode paintComponent überschreiben und auf dem übergebenen
Objekt des Typs Graphics entsprechende Methoden zum Zeichnen
aufrufen. Um eine eigene graphische Komponente zu definieren, wird empfohlen
die Klasse JPanel zu erweitern und in ihr die
Methode paintComponent zu überschreiben.
Beispiel:
Folgende Klasse definiert eine neue graphische Komponente, die zwei Linien, einen Text, ein Rechteck, ein Oval und ein gefülltes Kreissegment enthält.
SimpleGraphics
package name.panitz.gui.graphicsTest;
import javax.swing.JPanel;
import javax.swing.JFrame;
import java.awt.Graphics;
class SimpleGraphics extends JPanel{
public void paintComponent(Graphics g){
g.drawLine(0,0,100,200);
g.drawLine(0,50,100,50);
g.drawString("hallo",10,20);
g.drawRect(10, 10, 60,130);
g.drawOval( 50, 100, 30, 80);
g.fillArc(-20, 150, 80, 80, 0, 50);
}
}
Diese Komponente können wir wie jede andere Komponente auch einem
Fenster hinzufügen, so daß sie auf dem Bildschirm angezeigt werden
kann.
UseSimpleGraphics
package name.panitz.gui.graphicsTest;
import javax.swing.JFrame;
class UseSimpleGraphics {
public static void main(String [] args){
JFrame frame = new JFrame();
frame.getContentPane().add(new SimpleGraphics());
frame.pack();
frame.setVisible(true);
}
}
Wird dieses Programm gestartet, so öfnet Java das Fenster
aus Abbildung 2.4 auf dem Bildschirm.
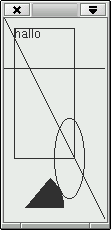
Erst wenn wir das Fenster mit der Maus größer
ziehen, können wir das ganze Bild sehen.
2.3.2 Dimensionen
Ärgerlich in unserem letzten Beispiel war, daß Java zunächst ein zu
kleines Fenster für unsere Komponente geöffnet hat, und wir dieses
Fenster mit Maus erst größer ziehen mußten. Die
Klasse JComponent enthält Methoden, in denen die Objekte
angeben können, welches ihre bevorzugte Größe bei ihrere Darstellung
ist. Wenn wir diese Methode überschreiben, so daß sie eine Dimension
zurückgibt, in der das ganze zu zeichnende Bild passt, so wird von
Java auch ein entsprechend großes Fenster geöffnet. Wir fügen der
Klasse SimpleGraphics folgende zusätzliche Methode hinzu.
public java.awt.Dimension getPreferredSize() {
return new java.awt.Dimension(100,200);
}
Jetzt öffnet Java ein Fenster, in dem das ganze Bild dargestellt
werden kann.
Aufgabe 4
(Punkteaufgabe 2 Punkte) Schreiben Sie eine
GUI-Komponente StrichKreis, die mit geraden Linien einen Kreis
entsprechend untenstehender Abbildung malt. Der Radius des Kreises
soll dabei dem Konstruktor der
Klasse StrichKreis als int-Wert
übergeben werden.
Testen Sie Ihre Klasse mit folgender Hauptmethode:
public static void main(String [] args) {
StrichKreis k = new StrichKreis(120);
JFrame f = new JFrame();
JPanel p = new JPanel();
p.add(new StrichKreis(120));
p.add(new StrichKreis(10));
p.add(new StrichKreis(60));
p.add(new StrichKreis(50));
p.add(new StrichKreis(70));
f.getContentPane().add(p);
f.pack();
f.setVisible(true);
}
Hinweis: In der Klasse java.lang.Math finden Sie Methoden
trigeometrischer Funktionen.
Insbesondere toRadians zum Umrechnen von Gardwinkel in Bogenmaß
sowie sin und cos.

2.3.3 Farben
In der graphische Komponente aus dem letzten Abschnitt haben wir uns
noch keine Gedanken über die Farbe der gezeichneten Grafik
gemacht. Die Klasse Graphics stellt eine Methode bereit, die
es erlaubt die Farbe des Stiftes für die Grafik auf einen bestimmten
Wert zu setzen. Alle anschließenden Zeichenbefehle auf das Objekt des
Typs Graphics werden dann mit dieser Farbe vorgenommen,
solange bis die Methode zum Setzen der Farbe ein weiteres Mal
aufgerufen wird. Die Methode zum Setzen der Farbe auf einem Objekt der
Klasse Graphics hat folgende Signatur:
public abstract void setColor(java.awt.Color c)
Zusätzlich gibt es für Komponenten noch eine Methode, die die
Hintergrundfarbe der Komponente beschreibt.
Farben werden mit der Klasse java.awt.Color beschrieben. Hier
gibt es mehrere Konstruktoren, um eine Farbe zu spezifizieren,
z.B. einen Konstruktor, der Intensität der drei
Grundfarben in einen Wert zwischen 0 und 255 festlegt.
Für bestimmte gängige Farben stellt die
Klasse Color Konstanten zur Verfügung, die wir benutzen
können, wie z.B.: Color.RED oder Color.GREEN.
Aufgabe 5
Erweitern Sie die Strichkreisklasse aus der letzten Aufgabe, so daß
jeder Strich in einer anderen Farbe gezeichnet wird.
Beispiel:
Wir können eine kleine Klasse schreiben, in der wir ein wenig mit Farben spielen. Wir setzen die Hintergrundfarbe des Objekts auf einen dunklen Grauwert, zeichnen darin ein dunkelgrünes Rechteck, ein rotes Oval und ein gelbes Oval.
ColorTest
package name.panitz.gui.graphicsTest;
import javax.swing.JPanel;
import javax.swing.JFrame;
public class ColorTest extends JPanel{
public ColorTest(){
//Hintergrundfarbe auf einen dunklen Grauton setzen
setBackground(new java.awt.Color(100,100,100));
}
public void paintComponent(java.awt.Graphics g){
//Farbe auf einen dunklen Grünton setzen
g.setColor(new java.awt.Color(22,178,100));
//Rechteck zeichnen
g.fillRect(25,50,50,100);
//Farbe auf rot setzen
g.setColor(java.awt.Color.RED);
g.fillOval(25,50,50,100);
//Farbe auf gelb setzen
g.setColor(java.awt.Color.YELLOW);
g.fillOval(37,75,25,50);
}
public java.awt.Dimension getPreferredSize() {
return new java.awt.Dimension(100,200);
}
public static void main(String [] _){
javax.swing.JFrame f = new JFrame("Farben");
f.getContentPane().add(new ColorTest());
f.pack();f.setVisible(true);
}
}
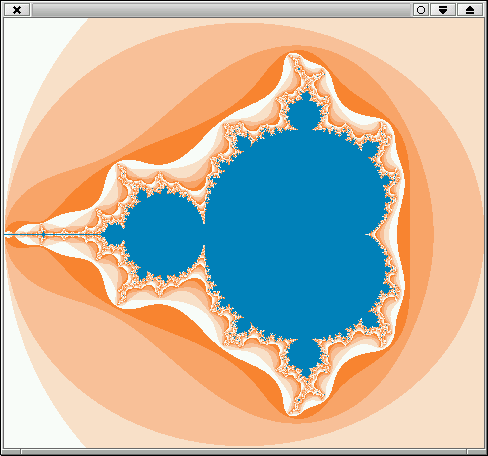
Das Programm ergibt das Bild aus Abbildung 2.6.

Fraktale
Um noch ein wenig mit Farben zu spielen, zeichnen wir in diesem
Abschnitt die berühmten Apfelmännchen. Apfelmännchen werden definiert
über eine Funktion auf komplexen Zahlen. Die aus der Mathematik
bekannten komplexen Zahlen sind Zahlen mit zwei reellen Zahlen als
Bestandteil, den sogenannten Imaginärteil und den sogenannten
Realteil. Wir schreiben zunächst eine rudimentäre Klasse zur
Darstellung von komplexen Zahlen:
Complex
package name.panitz.crempel.tool.apfel;
public class Complex{
Diese Klasse braucht zwei Felder um Real- und Imaginärteil zu speichern:
Complex
public double re; public double im;Ein naheliegender Konstruktor für komplexe Zahlen füllt diese beiden Felder.
Complex
public Complex(double re,double im){
this.re=re;this.im=im;
}
Im Mathematikbuch schauen wir nach, wie Addition und Multiplikation
für komplexe Zahlen definiert sind, und schreiben entsprechende Methoden:
Complex
public Complex add(Complex other){
return new Complex(re+other.re,im+other.im);
}
public Complex mult(Complex other){
return new Complex
(re*other.re-im*other.im,re*other.im+im*other.re);
}
Zusätzlich finden wir in Mathematik noch die Definition der Norm einer
komplexen Zahl und setzen auch diese Definition in eine Methode
um. Zum Quadrat des Realteils wird das Quadrat des Imaginärteils
addiert.
Complex
public double norm(){return re*re+im*im;}
}
Soweit komplexe Zahlen, wie wir sie für Apfelmännchen brauchen.
Grundlage zum Zeichnen von Apfelmännchen ist folgende
Iterationsgleichung auf komplexen Zahlen: zn+1 = zn2 + c.
Wobei z0 die komplexe Zahl 0+0i mit dem Real-
und Imaginärteil 0 ist.
Zum Zeichnen der Apfelmännchen wird ein Koordinatensystem so
interpretiert, daß die Achsen jeweils Real- und Imaginärteil von
komplexen Zahlen darstellen. Jeder Punkt in diesem Koordinatensystem
steht jetzt für die Konstante c in obiger Gleichung. Nun wir
geprüft ob und für welches n die Norm von zn größer
eines bestimmten Schwellwertes ist. Je nach der Größe von nwird der Punkt im Koordinatensystem mit einer anderen Farbe eingefärbt.
Mit diesem Wissen können wir nun versuchen die Apfelmännchen zu
zeichnen. Wir müssen nur geeignete Werte für die einzelnen Parameter
finden. Wir schreiben eine eigene Klasse für das graphische Objekt, in
dem ein Apfelmännchen gezeichnet wird. Wir deklarieren die Imports der
benötigten Klassen:
Apfelmaennchen
package name.panitz.crempel.tool.apfel;
import java.awt.Graphics;
import java.awt.Color;
import java.awt.Dimension;
import javax.swing.JFrame;
import javax.swing.JPanel;
public class Apfelmaennchen extends JPanel {
Als erstes deklarieren wir Konstanten für die Größe des
Apfelmännchens.
Apfelmaennchen
final int width = 480; final int height = 430;Eine weitere wichtige Konstante ist der Faktor, der angibt, welcher reellen Zahl ein Pixel entspricht:
Apfelmaennchen
double zelle=0.00625;Eine weitere Konstanten legt die Farbe fest, mit der die Punkte, die nicht über einen bestimmten Schwellwert konvergieren, eingefärbt werden sollen:
Apfelmaennchen
final Color colAppleman = new Color(0,129,190);Weitere Konstanten legen fest welche komplexe Zahl der Nullpunkt unseres Graphics-Objekts darstellt.
Apfelmaennchen
double startX = -2; double startY = -1.35;Weitere Konstanten sind der Schwellwert und die maximale Rekusrionstiefe n, für die wir jeweils zn berechnen:
Apfelmaennchen
final int recDepth = 50; final int schwellwert = 4;Die wichtigste Methode berechnet die Werte für die Gleichung zn+1 = zn2 + c. Der Eingabeparameter ist die komplexe Zahl c. Das Ergebnis dieser Methode ist das n, für das zn größer als der Schwellwert ist:
Apfelmaennchen
//C-Werte checken nach zn+1 = zn*zn + c,
public int checkC(Complex c) {
Complex zn = new Complex(0,0);
for (int n=0;n<recDepth;n=n+1) {
final Complex znp1 = zn.mult(zn).add(c);
if (znp1.norm() > schwellwert) return n;
zn=znp1;
}
return recDepth;
}
Jetzt gehen wir zum Zeichnen jedes Pixel
unseres Graphics-Objekts durch, berechnen welche komplexe
Zahl an dieser Stelle steht und benutzen dann die
Methode checkC, um zu berechnen ob und nach wieviel
Iterationen die Norm von zn größer als der Schwellwert
wird. Abhängig von dieser Zahl, färben wir den Punkt mit einer
Farbe ein.
Apfelmaennchen
public void paint(Graphics g) {
for (int y=0;y<height;y=y+1) {
for (int x=0;x<width;x=x+1) {
final Complex current
=new Complex(startX+x*zelle,startY+y*zelle);
final int iterationenC = checkC(current);
paintColorPoint(x,y,iterationenC,g);
}
}
}
Zur Auswahl der Farbe benutzen wir folgende kleine Methode, die
Abhängig von ihrem Parameter it an der
Stelle (x,y) einen Punkt in einer bestimmten Farbe zeichnet.
Apfelmaennchen
private void paintColorPoint
(int x,int y,int it,Graphics g){
final Color col
= it==recDepth
?colAppleman
:new Color(255-5*it%1,255-it%5*30,255-it%5* 50);
g.setColor(col);
g.drawLine(x,y,x,y);
}
Schließlich können wir noch die Größe festlegen und das Ganze in einer
Hauptmethode starten:
Apfelmaennchen
public Dimension getPreferredSize(){
return new Dimension(width,height);
}
public static void main(String [] args){
JFrame f = new JFrame();
f.getContentPane().add(new Apfelmaennchen());
f.pack();
f.setVisible(true);
}
}
Das Programm ergibt das Bild aus Abbildung 2.7.
2.3.4 Fonts und ihre Metrik
Ähnlich wie für Farben hat ein Objekt des
Typs Graphics auch einen aktuellen Font. Dieser ist vom
Typ java.awt.Font. Ebenso wie es die
Methoden getColor und setColor in der
Klasse Graphics gibt, gibt es dort auch
Methoden getFont und setFont.
Eine wichtige Information zu einem Font ist beim Zeichnen, wieviel
Platz ein bestimmter Text für in diesem Font benötigt. Hierzu
existiert eine Klasse java.awt.FontMetrics. Entsprechend gibt
es Methoden, die für ein Graphics-Objekt ein Objekt mit den
aktuellen FontMetrics-Objekt zurückgibt.
Beispiel:
Folgende Kleine Klasse vergrößert nach und nach den Font, und malt in verschiedenen Größen einen Text in ein Fenster.
FontTest
package name.panitz.gui.graphicsTest;
import java.awt.Font;
import java.awt.FontMetrics;
import java.awt.Graphics;
import java.awt.Dimension;
import javax.swing.JPanel;
import javax.swing.JFrame;
class FontTest extends JPanel {
public Dimension getPreferredSize(){
return new Dimension(250,650);
}
public void paintComponent(Graphics g){
//die y-Koordinate für einen Text
int where = 0;
//25 mal
for (int i=1; i<=25;i=i+1){
//nimm aktuellen Font und seine Maße
final Font f = g.getFont();
final FontMetrics fm = g.getFontMetrics(f);
//gehe die Höhe des Fonts weiter in Richtung x
where = where + (f.getSize()) ;
//male "hallo"
g.drawString("hallo",0,where);
//berechne wo der gerade gemalte String endet
//und male dort "welt"
g.drawString
("welt!",fm.stringWidth("hallo "),where);
//verändere die Fontgröße. Erhöhe sie um 1.
g.setFont(getFont().deriveFont(f.getSize2D()+1));
}
}
public static void main(String [] _){
JFrame f = new JFrame("Fonts");
f.getContentPane().add(new FontTest());
f.pack();
f.setVisible(true);
}
}
Das Programm ergibt das Bild aus Abbildung 2.8.

2.3.5 Erzeugen graphischer Dateien
Bisher haben wir alles auf dem Bildschirm in irgendeinen Fenster
gezeichnet. Das Schöne ist, daß wir die gleichen graphischen Objekte
jetzt benutzen können, um Graphiken in eine Datei zu schreiben.
Hierzu stellt Java die Klasse java.awt.image.RenderedImage zur Verfügung. Für Objekte dieser Klasse gibt es ein Objekt des
Typs Graphics. Man kann also ein RenderedImage-Objekt erzeugen und mit beliebige paint-Methoden auf
dessen Graphics-Objekt anwenden.
In der Klasse javax.imageio.ImageIO gibt
es schließlich Methoden, die es erlauben ein RenderedImagein eine Datei zu schreiben.
Beispiel:
Wir schreiben eine kleine Klasse mit Methoden, um das Bild einer graphischen Komponente in eine Datei zu speichern.
Zunächst brauchen wir eine ganze Reihe von Klassen, die wir importieren:
ComponentToFile
package name.panitz.gui.graphicsFile; import name.panitz.crempel.tool.apfel.Apfelmaennchen; import java.awt.image.BufferedImage; import java.awt.image.RenderedImage; import java.awt.Dimension; import java.awt.Graphics; import javax.imageio.ImageIO; import javax.swing.JComponent; import java.io.File; import java.io.IOException;
Wir schreiben eine Hauptmethode, die als Kommandozeilenparameter den
Namen der zu schreibenen Bilddatei übergeben bekommt:
ComponentToFile
public class ComponentToFile {
public static void main(String [] args){
Zu Testzwecken schreiben wir je eine png- und
eine jpg-Datei, in die wir die Komponente zeichnen wollen:
ComponentToFile
try {
final JComponent component = new Apfelmaennchen();
final RenderedImage image = createComponentImage(component);
ImageIO.write(image,"png", new File(args[0]+".png"));
ImageIO.write(image,"jpg", new File(args[0]+".jpg"));
}catch (IOException e) {System.out.println(e);}
}
Die folgende Methode erzeugt das eigentliche Bild der Komponente:
ComponentToFile
static public RenderedImage createComponentImage
(JComponent component) {
Wir erzeugen ein Bildobjekt in der für die Komponente benötigten Größe.
ComponentToFile
Dimension d = component.getPreferredSize();
BufferedImage bufferedImage
= new BufferedImage((int)d.getWidth(),(int)d.getHeight()
,BufferedImage.TYPE_INT_RGB);
Nun besorgen wir dessen Graphics-Umgebung:
ComponentToFile
Graphics g = bufferedImage.createGraphics();
Darin läßt sich unsere Komponente zeichnen:
ComponentToFile
component.paint(g);Die Methode kann das fertig gezeichnete Bild als Ergebnis zurückgeben:
ComponentToFile
return bufferedImage; } }
2.3.6 Graphics2D
Seit Java 1.2 existiert eine Unterklasse der
Klasse Graphics mit wesentlich mächtigeren Mehoden zum Zeichnen von
2-Dimenionalen Graphiken, die Klasse java.awt.Graphics2D. Leider
konnten nicht die Signaturen der entsprechenden Methoden paint in den
Komponentenklassen geändert werden, so daß dem
übergebene Graphics-Objekt zunächst zugesichert werden muß, daß es
sich um ein Graphics2D-Objekt handelt:
public void paint(Graphics g) {
Graphics2D g2 = (Graphics2D) g;
...
}
Graphics2D enthält Methoden zum Darstellen verschiedener Formen,
wahlweise umrandet oder gefüllt. Auf geometrische Formen können
Transformationen angewendet werden, einzelne Formen können kombiniert werden
zu komplexeren Figuren, Farbverläufe können definiert werden. Auch Text stellt
sich hierbei als geometrische Form dar.
Beispiel:
Folgende Klasse benutzt willkürlich ein paar Eigenschaften der Graphics2D-Klasse, um einen Eindruck über die Arbeitsweise dieser Klasse zu geben. Eine systematische Behandlung der graphischen ist nicht Gegenstand dieser Vorlesung.
G2DTest
package name.panitz.gui.g2d;
import javax.swing.JPanel;
import javax.swing.JFrame;
import java.awt.font.*;
import java.awt.*;
import java.awt.geom.*;
public class G2DTest extends JPanel{
int w = 550;
int h = 650;
public Dimension getPreferredSize(){
return new Dimension(w,h);}
public void paintComponent(Graphics g){
Graphics2D g2 = (Graphics2D) g;
TextLayout textTl
= new TextLayout
("Kommunismus", new Font("Helvetica", 1, 96)
, new FontRenderContext(null, false, false));
AffineTransform textAt = new AffineTransform();
textAt.translate(0,(float)textTl.getBounds().getHeight());
Shape shape = textTl.getOutline(textAt);
AffineTransform at = new AffineTransform();
at.rotate(Math.toRadians(45));
at.shear(1.5, 0.0);
g2.transform(at);
float dash[] = {10.0f};
g2.setStroke(
new BasicStroke
(3.0f, BasicStroke.CAP_BUTT
,BasicStroke.JOIN_MITER, 10.0f, dash, 0.0f)
);
g2.setPaint(
new GradientPaint(0,0,Color.black,w,h
,new Color(255,100,100),false)
);
g2.fill(shape);
g2.setColor(Color.darkGray);
g2.draw(shape);
}
public static void main(String [] _){
JFrame f = new JFrame("G2");
f.getContentPane().add(new G2DTest());
f.pack();
f.setVisible(true);
}
}
Das Programm öffnet das Fenster aus
Abbildung 2.9 auf dem Bildschirm.

2.4 Weitere Komponente und Ereignisse
Im Prinzip haben wir bisher alles kennengelernt um graphische Benutzerflächen
und Anwendungen zu beschreiben. Die Schwierigkeit bei graphischen Anwendungen
liegt hauptsächlich in der schieren Menge der unterschiedlichen Komponenten
und ihrem Zusammenspiel. Die Anzahl der vordefinierten Komponenten der
Swing-Bibliothek ist immens. Diese Komponenten können auf eine Vielzahl von
unterschiedlichen Ereignisarten reagieren. Bisher haben wir nur die
SChnittstelle ActionListener kennengelernt, die lediglich ganz
allgemein ein Ereignis behandelt.
In diesem Abschnitt schauen wir uns ein paar wenige weitere Komponenten und
Ereignistypen an.
2.4.1 Mausereignisse
Ein in modernen graphischen Oberflächen häufigst benutztes Eingabemedium ist
die Maus. Zwei verschiedene Ereignisarten sind für die Maus relevant:
- Mausereignisse, die sich auf das Drücken, Freilassen oder Klicken auf einen der Mausknöpfe bezieht. Hierfür gibt es eine Schnittstelle zur Behandlung solcher Ereignisse: MouseListener.
- Mausereignisse, die sich auf das Bewegen der Maus beziehen. Die Behandlung solcher Ereignisse kann über eine Implementierung der Schnittstelle MouseMotionListener spezifiziert werden.
Entsprechend gibt es für graphische Komponenten Methoden, um solche
Mausereignisbehandler der Komponente
hinzuzufügen: addMouseListener und addMouseMotionListener.
Um die Arbeit mit Ereignisbehandlern zu vereinfachen, gibt es für die
entsprechnden Schnittstellen im Paket java.awt.event prototypische
Implementierungen, in denen die Methoden der Schnittstelle so implementiert
sind, daß ohne Aktion auf die entsprechenden Ereignisse reagiert wird. Diese
prototypischen Implementierung sind Klassen, deren Namen
mit Adapter enden. So gibt es zur
Schnittstelle MouseListener die implementierende
Klasse MouseAdapter. Will man eine bestimmte Mausbehandlung
programmieren, reicht es aus, diesen Adapter zu erweitern und nur die Methoden
zu überschreiben, für die bestimmte Aktionen vorgesehen sind. Es erübrigt sich
dann für alle sechs Methoden der
Schnittstelle MouseListener Implementierungen vorzusehen.
Beispiel:
Wir erweitern die Klasse Apfelmaennchen um eine Mausbehandlung. Der mit gedrückter Maus markierte Bereich soll vergrößert in dem Fenster dargestellt werden.
ApfelWithMouse
package name.panitz.crempel.tool.apfel;
import java.awt.Graphics;
import java.awt.event.*;
import javax.swing.JFrame;
public class ApfelWithMouse extends Apfelmaennchen{
public ApfelWithMouse(){
Im Konstruktor fügen wir der Komponente eine Mausbehandlung hinzu. Der
Mausbehandler merkt sich die Koordinaten, an denen die Maus gedrückt wird
und berechnet beim Loslassen des Mausknopfes den neuen darzustellenden Zahlenbereich:
ApfelWithMouse
addMouseListener(new MouseAdapter(){
int mouseStartX=0;
int mouseStartY=0;
public void mousePressed(MouseEvent e) {
mouseStartX=e.getX();
mouseStartY=e.getY();
}
public void mouseReleased(MouseEvent e) {
int endX = e.getX();
int endY = e.getY();
startX = startX+(mouseStartX*zelle);
startY = startY+(mouseStartY*zelle);
zelle = zelle*(endX-mouseStartX)/width;
repaint();
}
});
}
Auch für diese Klasse sehen wir eine kleine Startmethode vor:
ApfelWithMouse
public static void main(String [] _){
JFrame f = new JFrame();
f.getContentPane().add(new ApfelWithMouse());
f.pack();
f.setVisible(true);
}
}
2.4.2 Fensterereignisse
Auch für Fenster in einer graphischen Benutzeroberfläche existieren eine Reihe
von Ereignissen. Das Fenster kann minimiert oder maximiert werden, es kann das
aktive Fenster oder im Hintergrund sein und es kann schließlich auch
geschlossen werden. Um die Reaktion auf solche Ereignisse zu spezifizieren
existiert die Schnittstelle WindowListener mit entsprechender
prototypischer Adapterklasse WindowAdapter. Die Objekte der
Fensterereignisbehandlung können mit der
Methode addWindowListener Fensterkomponenten hinzugefügt werden.
Beispiel:
In den bisher vorgestellten Programmen wird Java nicht beendet, wenn das einzige Fenster der Anwendung geschlossen wurde. Man kann an der Konsole sehen, daß der Javainterpreter weiterhin aktiv ist. Das liegt daran, daß wir bisher noch nicht spezifiziert haben, wie die Fensterkomponenten auf das Ereignis des Schließens des Fensters reagieren sollen. Dieses kann mit einem Objekt, das WindowListener implementiert in der Methode windowClosing spezifiziert werden. Wir schreiben hier eine Version des Apfelmännchenprogramms, in dem das Schließen des Fensters den Abbruch des gesammten Programms bewirkt.
ClosingApfelFrame
package name.panitz.crempel.tool.apfel;
import javax.swing.JFrame;
import java.awt.event.*;
public class ClosingApfelFrame {
public static void main(String [] args){
JFrame f = new JFrame();
f.getContentPane().add(new ApfelWithMouse());
f.addWindowListener(new WindowAdapter(){
public void windowClosing(WindowEvent e) {
System.exit(0);
}
});
f.pack();
f.setVisible(true);
}
}
2.4.3 Weitere Komponenten
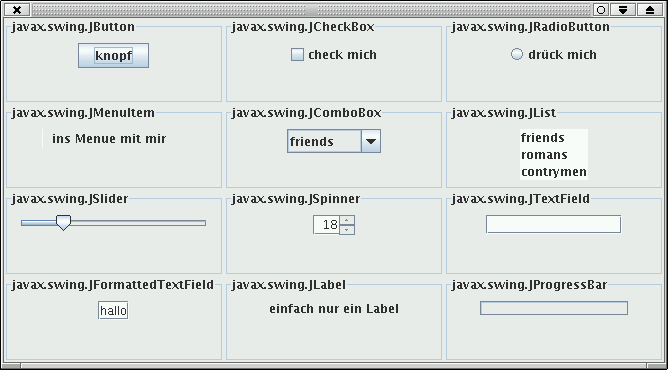
Um einen kleinen Überblick der vorhandenen Swing Komponenten zu bekommen,
können wir ein kleines Programm schreiben, daß möglichst viele Komponenten
einmal instanziiert. Hierzu schreiben wir eine kleine Testklasse:
ComponentOverview
package name.panitz.gui.example;
import javax.swing.*;
import java.awt.*;
import java.util.*;
public class ComponentOverview {
public ComponentOverview(){
Darin definieren wir eine Reihung von einfachen Swing-Komponenten:
ComponentOverview
JComponent [] cs1 =
{new JButton("knopf")
,new JCheckBox("check mich")
,new JRadioButton("drück mich")
,new JMenuItem("ins Menue mit mir")
,new JComboBox(combos)
,new JList(combos)
,new JSlider(0,350,79)
,new JSpinner(new SpinnerNumberModel(18,0.0,42.0,2.0))
,new JTextField(12)
,new JFormattedTextField("hallo")
,new JLabel("einfach nur ein Label")
,new JProgressBar(0,42)
};
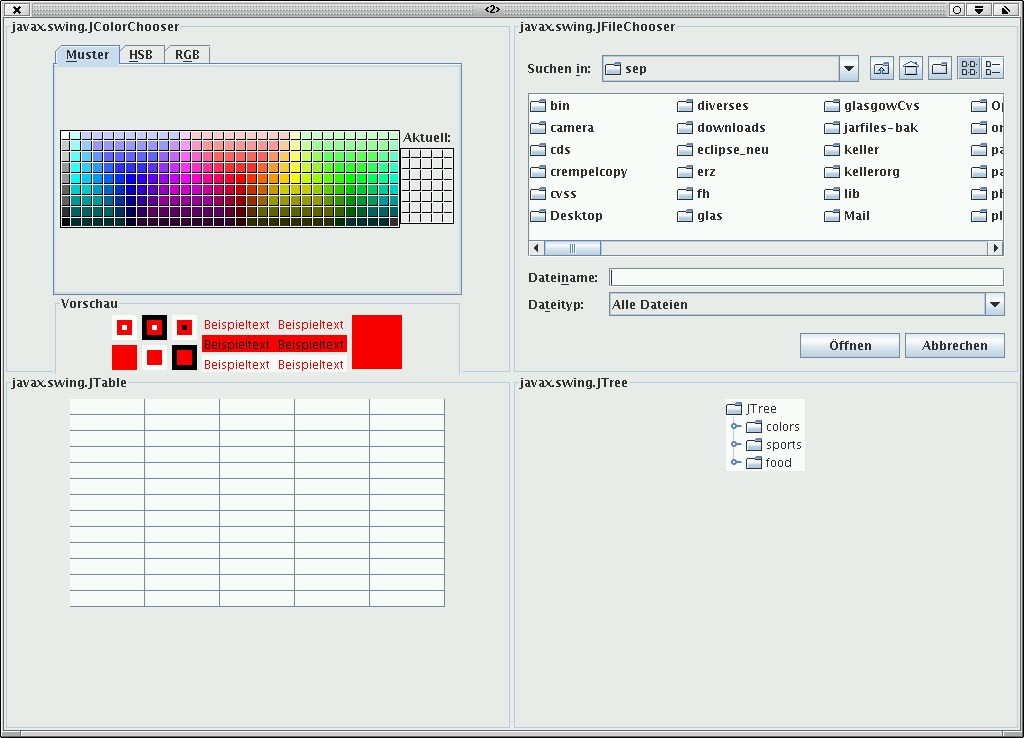
Sowie eine zweite Reihung von komplexeren Swing-Komponenten:
ComponentOverview
JComponent [] cs2 =
{new JColorChooser(Color.RED)
,new JFileChooser()
,new JTable(13,5)
,new JTree()
};
Diese beiden Reihungen zeigen sollen mit einer Hilfsmethode
in einem Fenster angezeigt werden:
ComponentOverview
displayComponents(cs1,3); displayComponents(cs2,2); }
Für die Listen- und Auswahlkomponenten oben haben wir eine Reihung von
Strings benutzt:
ComponentOverview
String [] combos = {"friends","romans","contrymen"};
Bleibt die Methode zu schreiben, die die Reihungen von Komponenten anzeigen
kann. Als zweites Argument bekommt diese Methode übergeben, in wieviel Spalten
die Komponenten angezeigt werden sollen.
ComponentOverview
public void displayComponents(JComponent [] cs,int col){
Ein Fenster wird definiert, für das eine Gridlayout-Zwischenkomponente mit
genügend Zeilen erzeugt wird:
ComponentOverview
JFrame f = new JFrame();
JPanel panel = new JPanel();
panel.setLayout(
new GridLayout(cs.length/col+(cs.length%col==0?0:1),col));
Für jede Komponente wird ein Panel mit Rahmen und den Klassennamen
der Komponente als Titel erzeugt und der Zwischenkomponente hinzugefügt:
ComponentOverview
for (JComponent c:cs){
JPanel p = new JPanel();
p.add(c);
p.setBorder(BorderFactory
.createTitledBorder(c.getClass().getName()));
panel.add(p);
}
Schließlich wird noch das Hauptfester zusammengepackt:
ComponentOverview
f.getContentPane().add(panel);
f.pack();
f.setVisible(true);
}
Und um alles zu starten, noch eine kleine Hauptmethode:
ComponentOverview
public static void main(String [] _){
new ComponentOverview();
}
}
Wir erhalten einmal die Übersicht von Komponenten wie in
Abbildung 2.10 und einmal wie
in Abbildung 2.11 dargestellt.
Womit wir uns noch nicht im einzelnen beschäftigt haben, ist das Datenmodell,
das hinter den einzelnen komplexeren Komponenten steht. Im nächsten
Hauptkapitel werden insbesondere Bäume als Datenstruktur, die auch in einer
graphischen Komponente darstellbar ist, untersucht werden.
2.5 Swing und Steuerfäden
In der GUI-Programmierung kommt es oft vor, daß Dinge nebenläufig verlaufen
sollen. Hierzu kennen wir das Prinzip von Steuerfäden. Und tatsächlich
scheinen viele Dinge in unseren GUIs bisher schon nebenläufig zu
funktionieren.
Die verschiedenen Objekte zur Ereignisbehandlung fragen nebenläufig ab, ob
ein Ereignis aufgetreten ist, auf das sie reagieren sollen oder
nicht. Solange man nur diese Nebenläufigkeit nutzt, die in Swing quasi für die
Ereignisbehandlung fest eingebaut ist, so bekommt man keine problematischen
Fälle. Im Java Handbuch von Sun[CWH00] gibt es daher
eine erste große Empfehlung im
bezug auf Steuerfäden:
The first rule of using threads is this: avoid them when you can.
Oft braucht man aber Nebenläufigkeit. Wobei man zwei große
Anwendungsfälle identifizieren kann, in denen in einem GUI Nebenläufigkeit
wünschenswert ist.
- Bestimmte Operationen können sehr lange dauern und damit das GUI blockieren. Das Laden oder Bearbeiten von Multimediadateien kann unter Umständen sehr lange dauern. Während dieser Zeit, werden Fensterinhalte nicht aktualisiert.
- Für Animationen soll nach bestimmten Zeitintervallen die Graphik eines GUIs verändert und neu gezeichnet werden. Hierzu benötigt man so etwas wie ein sleep der Steuerfäden.
Beispiel:
Wir können uns zunächst davon überzeugen, daß die einzelnen Komponenten in einer Swinganwendung nicht in einzelnen Steuerfäden laufen. Hierzu schreiben wir ein Programm mit zwei Knopfkomponenten, von denen der eine eine Ereignisbehandlung hat, die nicht terminiert.
GuiHangs
package name.panitz.swing.threadTest;
import javax.swing.JFrame;
import javax.swing.JButton;
import java.awt.event.*;
public class GuiHangs {
public static void main(String [] _){
JFrame f1 = new JFrame("f1");
JFrame f2 = new JFrame("f2");
JButton b1 = new JButton("b1");
JButton b2 = new JButton("b2");
b1.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent _){
System.out.println("b1 action");
}
});
b2.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent _){
System.out.println("b2 action");
while (true){}
}
});
f1.getContentPane().add(b1);
f2.getContentPane().add(b2);
f1.pack();
f2.pack();
f1.setVisible(true);
f2.setVisible(true);
}
}
Starten wir dieses Programm, so werden zunächst zwei Fenster mit Knöpfen
geöffnet. Sobald der Knopf b2 das erste Mal gedrückt wird, hängt
die komplette Anwendung. Es können keine Aktionen mehr durchgeführt werden
und die Fenster werden auch nicht mehr neu gezeichnet.
Leider ist Swing so konzipiert, daß man nicht auf naive Weise eigene Objekte
vom Typ Thread erzeugen und nebenläufig starten kann. Man spricht
davon, daß Swing nicht thread safe ist. Insbesondere in den
Zeichenmethoden der Komponenten, wie paintComponent darf man nicht
eigene Steuerfäden benutzen. Das GUI könnte sich sonst mit den Steuerfäden zur
Ereignisbehandlung in den Zeichenmethoden zur Darstellung der Komponenten auf
unkontrollierte Weise verwurschteln.
Um einen sicheren Umgang mit Steuerfäden zu gewährleisten, stellt Swing ein
paar Hilfsklassen zur Verfügung, die die wichtigen Anwendungsfälle für
Steuerfäden in GUIs abdecken. Diese Hilfsklasse sorgen dafür, daß weitere
Steuerfäden immer mit den Steuerfäden zur Ereignisbehandlung konform sind.
2.5.1 Timer in Swing
Um zeitlich immer wiederkehrende Ereignisse in GUIs zu prgrammieren gibt in
Swing eine Hilfsklasse Timer. Objekte dieser Klasse können so
instanziiert werden, daß sie in bestimmten Zeitabständen Ereignisse
auslösen. Der Timer ist also so etwas wie ein
Ereignisgenerator. Zusätzlich gibt man einem Timer-Objekt auch
einen ActionListener mit, der spezifiziert, wie auf diese in
zeitintervallen auftretenen Ereignisse reagiert werden soll.
Aufgabe 6
(2 Punkte)
Implementieren Sie eine Analoguhr. Das Ziffernblatt dieser Uhr können
Sie dabei mit den Methoden auf einem Graphics-Objekt zeichnen, oder
Sie können versuchen eine Bilddatei zu laden und das Ziffernblatt als Bild
bereitstellen. Als Anregung für ein Ziffernblatt können Sie sich das Bild
des
Ziffernblatts der handgefertigten Sekundenuhr (http://www.panitz.name/prog2/examples/images/wiebking.jpg) des Uhrmachers
G.Wiebking herunterladen.
Beispiel:
Folgende Klasse implementiert eine simple Uhr. In einem JLabel wird die aktuelle Zeit angegeben. Die Komponente wird einem Timer übergeben, der jede Sekunde eine neues Ereigniserzeugt. Diese Ereignisse sorgen dafür, daß die Zeit im Label aktualisiert wird.
Uhr
package name.panitz.swing.threads; import javax.swing.*; import java.util.Date; import java.awt.event.*;Die Klasse Uhr ist nicht nur ein JPanel, in dem ein JLabel benutzt wird, Datum und Uhrzeit anzuzeigen, sondern implementiert gleichfalls auch einen ActionListener.
Uhr
public class Uhr extends JPanel implements ActionListener{
Zunächst sehen wir das Datumsfeld für diese Komponente vor:
Uhr
JLabel l = new JLabel(new Date()+"");Im Konstruktor erzeugen wir ein Objekt vom Typ Timer. Dieses Objekt soll alle Sekunde (alle 1000 Millisekunden) ein Ereignis erzeugen. Dem Timer wird das gerade im Konstruktor erzeute Objekt vom Typ Uhr übergeben, das, da es ja einen ActionListener implementiert, auf diese Ereignisse reagieren soll.
Uhr
public Uhr (){
new Timer(1000,this).start();
add(l);
}
Um die Schnittstelle ActionListener korrekt zu implementieren, muß
die Methode actionPerformed implementiert werden. In dieser setzen
wir jeweils Datum und Uhrzeit mit dem aktuellen Wert neu ins Label.
Uhr
public void actionPerformed(ActionEvent _){
l.setText(""+new Date());
}
Und natürlich sehen wir zum Testen eine kleine Hauptmethode vor, die die Uhr
in einem Fensterrahmen anzeigt.
Uhr
public static void main(String [] _){
JFrame f = new JFrame();
f.getContentPane().add(new Uhr());
f.pack();
f.setVisible(true);
}
}
Das so erzeugte Fenster mit einer laufenden Uhr findet sich in
Abbildung 2.12 dargestellt.
Animationen mit Timern
Mit dem Prinzip des Timers können wir jetzt auf einfache Weise Animationen
realisieren. In einer Animation bewegt sich etwas. Dieses drücken wir durch
eine entsprechende Schnittstelle aus:
Animation
package name.panitz.animation;
public interface Animation {
public void move();
}
Wir wollen einen besonderen JPanel realisieren, in dem sich etwas
bewegen kann. Damit soll ein solcher JPanel auch eine Animation
sein. Es bietet sich an, eine abstrakte Klasse zu schreiben, in der die
Methode move noch nicht implementiert ist:
AnimatedJPanel
package name.panitz.animation;
import javax.swing.JPanel;
import javax.swing.Timer;
import java.awt.event.*;
public abstract class AnimatedJPanel
extends JPanel implements Animation {
Um zeitgesteuert das Szenario der Animation zu verändern, brauchen wir
einen Timer.
AnimatedJPanel
Timer t;
Im Konstruktor wird dieser initialisiert. Als Ereignisbehandlung wird ein
Ereignisbehandlungsobjekt erzeugt, das die Methode move aufruft, also
dafür sorgt, daß die Szenerie sich weiterbewegt und das dafür sorgt, daß die
Szenerie neu gezeichnet wird. Wir starten diesen Timer gleich.
AnimatedJPanel
public AnimatedJPanel(){
super(true);
t = new Timer(29,new ActionListener(){
public void actionPerformed(ActionEvent _){
move();
repaint();
}
});
t.start();
}
}
Jetzt können wir durch implementieren der Methode move und
Überschreiben der Methode paintComponent beliebige Animationen
erzeugen. Als erstes schreiben wir eine Klasse in der ein Kreis sich auf und
ab bewegt:
BouncingBall
package name.panitz.animation;
import java.awt.Graphics;
import java.awt.Dimension;
import java.awt.Color;
import javax.swing.JFrame;
public class BouncingBall extends AnimatedJPanel {
Die Größe des Kreises und des Spielfeldes setzen wir in Konstanten fest:
BouncingBall
final int width = 100; final int height = 200; final int ballSize = 20;Der Ball soll sich entlang der y-Achse bewegen, und zwar pro Bild um 4 Pixel:
BouncingBall
int yDir = 4;
Anfangs soll der Ball auf der Hälfte der x-Achse liegen und ganz oben im Bild
liegen:
BouncingBall
int ballX = width/2-ballSize/2; int ballY = 0;Wir bewegen den Ball. Wenn er oben oder unten am Spielfeldrand anstößt, so ändert er seine Richtung:
BouncingBall
public void move(){
if (ballY>height-ballSize || ballY<0) yDir=-yDir;
ballY=ballY+yDir;
}
Zum Zeichnen, wird ein roter Hintergrund gezeichnet und der Kreis an seiner
aktuellen Position.
BouncingBall
public void paintComponent(Graphics g){
g.setColor(Color.RED);
g.fillRect(0,0,width,height);
g.setColor(Color.YELLOW);
g.fillOval(ballX,ballY,ballSize,ballSize);
}
Unsere Größe wird verwendet als bevorzugte Größe der Komponente:
BouncingBall
public Dimension getPreferredSize(){
return new Dimension(width,height);
}
Und schließlich folgt eine kleine Hauptmethode zum Starten der Animation.
BouncingBall
public static void main(String [] _){
JFrame f = new JFrame("");
f.getContentPane().add(new BouncingBall());
f.pack();
f.setVisible(true);
}
}
Aufgabe 7
Schreiben Sie eine Animation, in der zwei Kreise sich bewegen. Die
Kreise sollen an den Rändern der Spielfläche abprallen und sie sollen
ihre Richtung ändern, wenn sie sich berühren.
Aufgabe 8
Schreiben Sie eine Animation, deren Verhalten über Mausklicks
beeinflussen können.
2.5.2 SwingWorker für Steuerfäden in der Ereignisbehandlung
Sun bietet eine Beispielimplementierung einer Hilfsklasse an, die es erlaubt,
Code in einen eigenen Steuerfaden zu verpacken. Die
Klasse SwingWorker. SwingWorker ist nicht Bestandteil des
offiziellen Swing APIs, sondern lediglich im Tutorial angegeben. Im Anhang des
Skripts ist die Klasse SwingWorker abgedruckt.
Die Klasse SwingWorker ist dazu gedacht, Code innerhalb einer
Ereignisbehandlungsmethode, dessen Ausführung
lange dauern kann, in einen Steuerfaden zu kapseln. Statt den Code direkt in
der Ereignisbehandlungsmethode zu schreiben:
public void actionPerformed(ActionEvent e) {
...
//...Code, der sehr lange dauert ...
...
}
Ist er in die Methode construct einer SwingWorker-Instanz zu
kapseln:
public void actionPerformed(ActionEvent e) {
...
final SwingWorker worker = new SwingWorker() {
public Object construct() {
//...Code, der sehr lange dauert, ist jetzt hier...
return someValue;
}
};
worker.start();
...
}
Beispiel:
Jetzt können wir unser Eingangsbeispiel mit der SwingWorker-Klasse so umschreiben, daß es nicht mehr zum Hängen des gesamten Programms kommt.
GuiHangsNoLonger
package name.panitz.swing.threadTest;
import javax.swing.JFrame;
import javax.swing.JButton;
import java.awt.event.*;
public class GuiHangsNoLonger {
public static void main(String [] _){
JFrame f1 = new JFrame("f1");
JFrame f2 = new JFrame("f2");
JButton b1 = new JButton("b1");
JButton b2 = new JButton("b2");
b1.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent _){
System.out.println("b1 action");
}
});
b2.addActionListener(new ActionListener(){
public void actionPerformed(ActionEvent _){
final SwingWorker worker = new SwingWorker() {
public Object construct() {
System.out.println("b2 action");
int x = 1; while (true){if (x==0) break;}
return null;
}
};
worker.start();
}
});
f1.getContentPane().add(b1);
f2.getContentPane().add(b2);
f1.pack();
f2.pack();
f1.setVisible(true);
f2.setVisible(true);
}
}
Nach Drücken des Knopfes b2 bleibt das Gui weiterhin voll
funktionsfähig. Allerdings stellt man fest, indem man sich z.B.
mit top die laufenden Prozesse in einem Unixsystem anschaut, daß
jedes Drücken des Knopfes einen neuen Unterprozess von Java erzeugt.
SwingWorkerbeispiel
Im folgenden ist ein weiteres Beispiel angegeben, in dem die
Klasse SwingWorker benutzt wird. Diesmal soll eine Bilddatei geladen
werden. Hierzu schreiben wir eine Klasse, die von JLabel ableitet.
Das Label soll eine vorgegebene feste Größe haben.
Dem Konstruktor wird eine Bilddatei übergeben.
ImageIcon
package name.panitz.gui;
import java.io.File;
import java.net.MalformedURLException;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class ImageIcon extends JLabel {
private int height = 60;
private int width = 80;
final Toolkit toolkit = Toolkit.getDefaultToolkit();
private Image image;
public ImageIcon(String fileName){this(new File(fileName));}
public ImageIcon(final File file){
setImage(file);
}
Zum Setzen des Bildes, wird die Bilddatei gelesen, um es dann auf die
vorgegebene Größe zu skalieren:
ImageIcon
public void setImage(File jpgFile){
try{
image=toolkit.getImage(jpgFile.toURL());
final MediaTracker tracker = new MediaTracker(this);
tracker.addImage(image, 0,width,height);
try {tracker.waitForAll();}
catch (Exception e) {e.printStackTrace();}
fitImage();
setIcon(new javax.swing.ImageIcon(image));
}catch (MalformedURLException e){}
}
Zum Skalieren ist zunächst die Originalgröße zu lesen, die skalierte Größe zu
berechnen und schließlich das Bild auf die skalierte Größe zu setzen:
ImageIcon
private void fitImage(){
final int w = image.getWidth(this);
final int h = image.getHeight(this);
final int w1 = width; final int h1 = h*width/w;
final int w2 = w*height/h; final int h2 = height;
final int w3 = w1<w2?w1:w2; final int h3 = h1<h2?h1:h2;
image=image.getScaledInstance
(w3<w?w3:w,h3<h?h3:h,Image.SCALE_FAST);
}
}
Damit haben wir eine Komponente, die Bilder beliebiger Größe aus Dateien in
einer vorgegebenen Größe anzeigen kann. Diese Komponente
können wir benutzen, um eine kleine Anwendung zu
starten. Die Anwendung soll zwei Fenster Öffnen: im erstem
Fenster sollen alle über die Kommandozeile mitgegebenen Biler als Label
angezeigt werden, im zweitem Fenster soll eine Uhr laufen:
UseImageIcon
package name.panitz.gui;
import name.panitz.swing.threads.Uhr;
import java.io.File;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
class UseImageIcon {
public static void main(String [] args){
JFrame f= new JFrame();
final JPanel p = new JPanel();
f.getContentPane().add(p);
final int c = 10;
final int n = args.length;
p.setLayout(new GridLayout(n/c+((n%c)==0?0:1),c));
for (final String arg:args)p.add(new ImageIcon(arg));
f.pack();
f.setVisible(true);
JFrame f2 = new JFrame();
f2.getContentPane().add(new Uhr());
f2.pack();
f2.setVisible(true);
}
}
Wenn wir dieses Programm mit allen unseren Urlaubsbildern starten, dann
stellen wir fest, daß es sehr lange dauert, bis sich die beiden Fenster
öffnen. Erst wenn alle Bilder geladen und skaliert sind, werden die beiden
Fenster geöffnet. Auch dieses Programm läßt sich mit Hilfe der
Klasse SwingWorker verbessern. Das Erzeugen der Objekte vom
Typ ImageIcon wird hierzu in
einem ActionListener durchgeführt. Es wird
ein Timer benutzt, der genau ei Ereignis erzeugt, so daß der
Ereignisbehandler genau einmal auf diesen Timer reagieren kann.
BetterUseOfImageIcon
package name.panitz.gui;
import name.panitz.swing.threads.Uhr;
import name.panitz.swing.threadTest.SwingWorker;
import java.io.File;
import java.awt.*;
import java.awt.event.*;
import javax.swing.*;
public class BetterUseOfImageIcon{
public static void main(String [] args){
final JFrame f= new JFrame();
final JPanel p = new JPanel();
f.getContentPane().add(p);
final int c = 10;
final int n = args.length;
p.setLayout(new GridLayout(n/c+((n%c)==0?0:1),c));
for (final String arg:args){
ActionListener listen = new ActionListener(){
public void actionPerformed(ActionEvent e) {
final SwingWorker worker = new SwingWorker() {
public Object construct() {
p.add(new ImageIcon(arg)); f.pack();
f.repaint();
return null;
}
};
worker.start();
}
};
Timer t = new Timer(10,listen);
t.setRepeats(false);
t.start();
}
f.pack();
f.setVisible(true);
JFrame f2 = new JFrame();
f2.getContentPane().add(new Uhr());
f2.pack();
f2.setVisible(true);
}
}
Und tatsächlich: starten wir dieses Programm jetzt mit vielen Bilddateien, so
öffnen sich gleich beide Bilder und die Uhr läuft durch. Nach und nach
erscheinen die Bilder in ihrem Fenster, jedes solbald es erfolgreich geladen
und skaliert wurde.
Chapter 3
Chapter 3
Abstrakte Datentypen
3.1 Bäume
Bäume sind ein gängiges Konzept um hierarchische Strukturen zu
modellieren. Sie sind bekannt aus jeder Art von Baumdiagramme, wie
Stammbäumen oder Firmenhierarchien.
In der Informatik
sind Bäume allgegenwärtig. Fast alle komplexen Daten
stellen auf die eine oder andere Art einen Baum dar. Beispiele für
Bäume sind mannigfach:
- Dateisystem: Ein gängiges Dateisystem, wie es aus Unix, MacOS und Windows bekannt ist, stellt eine Baumstruktur dar. Es gibt einen ausgezeichneten Wurzelordner, von dem aus zu jeder Datei einen Pfad existiert.
- Klassenhierarchie: Die Klassen in Java stellen mit ihrer Ableitungsrelation eine Baumstruktur dar. Die Klasse Object ist die Wurzel dieses Baumes, von der aus alle anderen Klassen über einen Pfad entlang der Ableitungsrelation erreicht werden können.
- XML: Die logische Struktur eines XML-Dokuments ist ein Baum. Die Kinder eines Elements sind jeweils die Elemente, die durch das Element eigeschlossen sind.
- Parserergebnisse: Ein Parser, der gemäß einer Grammatik prüft, ob ein bestimmter Satz zu einer Sprache gehört, erzeugt im Erfolgsfall eine Baumstruktur. Im nächsten Kapitel werden wir dieses im Detail kennenlernen.
- Listen: Auch Listen sind Bäume, allerdings eine besondere Art, in denen jeder Knoten nur maximal ein Kind hat.
- Berechnungsbäume: Zur statischen Analyse von Programmen, stellt man Bäume auf, in denen die Alternativen eines bedingten Ausdrucks Verzweigungen im Baum darstellen.
- Tableaukalkül: Der Tableaukalkül ist ein Verfahren zum Beweis logischer Formeln. Die dabei verwendeten Tableaux sind Bäume.
- Spielbäume: Alle möglichen Spielverläufe eines Spiels können als Baum dargestellt werden. Die Kanten entsprechen dabei einem Spielzug.
- Prozesse: Auch die Prozesse eines Betriebssystems stellen eine Baumstruktur dar. Die Kinder eines Prozesses sind genau die Prozesse, die von ihm gestartet wurden.
Wie man sieht, lohnt es sich, sich intensiv mit Bäumen vertraut zu
machen, und man kann davon ausgehen, was immer in der Zukunft neues in
der Informatik entwickelt werden wird, Bäume werden darin in
irgendeiner Weise eine Rolle spielen.
Ein Baum besteht aus einer Menge von Knoten die durch gerichtete
Kanten verbunden sind. Die Kanten sind eine Relation auf den Knoten
des Baumes. Die Kanten verbinden jeweils einen Elternknoten
mit einem Kinderknoten. Ein Baum hat einen eindeutigen
Wurzelknoten. Dieses ist der einzige Knoten, der keinen Elternknoten
hat, d.h. es gibt keine Kante, die zu diesen Knoten
führt. Knoten, die keinen Kinderknoten haben, d.h. von
denen keine Kante ausgeht, heißen Blätter.
Die Kinder eines Knotens sind geordnet, d.h. sie stehen
in einer definierten Reihenfolge.
Eine Folge von Kanten, in der der Endknoten einer Vorgängerkante der
Ausgangsknoten der nächsten Kanten ist, heißt Pfad.
In einem Baum darf es keine Zyklus geben, das heißt, es darf keinen
Pfad geben, auf dem ein Knoten zweimal liegt.
Knoten können in Bäumen markiert sein, z.B. einen Namen
haben. Mitunter können auch Kanten eine Markierung tragen.
Bäume, in denen Jeder Knoten maximal zwei Kinderknoten hat, nennt man
Binärbäume. Bäume, in denen jeder Knoten maximal einen Kinderknoten
hat, heißen Listen.
3.1.1 Formale Spezifikation
Allgemeine Bäume
Wir wollen in diesem Abschnitt Bäume als einen abstrakten Datentypen
spezifizieren.
Konstruktoren
Abstrakte Datentypen lassen sich durch
ihre Konstruktoren spezifizieren. Die
Konstruktoren geben an, wie Daten des entsprechenden Typs konstruiert
werden können.
In dem Fall von Bäumen bedarf es nach
den obigen Überlegungen nur eines Konstruktors, den für Knoten. Er
konstruiert aus der Liste der Kinderbäume einen neuen Baumknoten.
Als zusätzliches Argument bekommt er ein Objekt, das eine Markierung
für den Baumknoten darstellt. Den Typ dieses Markierungsobjektes können wir
erst einmal offen lassen. Hier darf ein beliebiger Typ gewählt werden.
Wir benutzen in der Spezifikation eine mathematische Notation der
Typen von Konstruktoren.3 Dem Namen des Konstruktors folgt dabei mit einem
Doppelpunkt abgetrennt der Typ. Der Ergebnistyp wird von den
Parametertypen mit einem Pfeil getrennt.
Somit läßt sich der Typ des Konstruktors für Bäume wie
folgt spezifizieren:
- Node: (a,List<Tree<a>>) ®Tree<a>
Selektoren
Die Selektoren können wieder auf die einzelnen
Bestandteile der Konstruktion zurückgreifen.
Der Konstruktor Node hat zwei Parameter.
Für Bäume
werden zwei
Selektoren spezifiziert, die jeweils einen dieser beiden Parameter
wieder aus dem Baum selektieren.
- theChildren: Tree<a>®List<Tree<a>>
- mark: Tree<a>®a
Der funktionale Zusammenhang von den Selektoren und Konstruktoren läßt
sich durch folgende Gleichungen spezifizieren:
mark(Node(x,xs)) = x
theChildren(Node(x,xs)) = xs
Testmethoden
Da wir nur einen Konstruktor vorgesehen haben, brauchen wir keine
Testmethode, die unterscheidet, mit welchem Konstruktor ein Baum
konstruiert wurde.
Die Unterscheidung, ob es sich um ein Blatt oder um
einen Knoten mit Kindern handelt, läßt sich über die Abfrage, ob die
Liste der Kinderknoten leer ist, erfahren. Wir können eine
entsprechende Funktion spezifizieren:
isLeaf(Node(x,xs)) = isEmpty(xs)
3.1.2 Modellierung
Wir haben wieder verschiedene Möglichkeiten eine Baumstruktur mit
Klassen zu modellieren.
mit einer Klasse
Die einfachste Modellierung ist mit einer
Klasse. Diese Klasse stellt einen Knoten dar. Sie enthält ein Feld
für die Knotenmarkierung und ein Feld für die Kinder des Knotens. Nach
unserer Spezifikation sind die Kinder eine Liste weiterer Knoten.
Ein entsprechendes UML Diagramm befindet sich in
Abbildung 3.1

Mit einer Klassenhierarchie
Ebenso, wie wir es bei Listen vorgeschlagen haben, können wir auch
wieder eine Modellierung mit mehreren Klassen vornehmen. Hierzu
beschreibt eine Schnittstelle die allgemeine Funktionalität von
Bäumen. Zwei Unterklassen, jeweils eine für innere Knoten und eine für
Blätter implementieren diese Schnittstelle.
Ein entsprechendes UML Diagramm befindet sich in
Abbildung 3.2
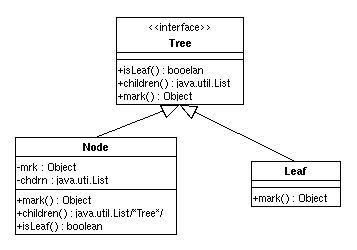
Welche dieser beiden Modellierungen jeweils vorzuziehen ist, hängt
sehr davon ab, für was die Bäume in der Gesammtanwendung benutzt
werden sollen. Eine grobe Faustregel für abstrakte Datentypen ist:
- Wenn zu erwarten ist, daß im Laufe der Softwareentwicklung noch weitere Konstruktoren zum abstrakten Datentyp hinzudefiniert werden, dann ist eine Modellierung als Hierarchie vorteilhaft. Der neue Konstruktor führt zu einer neuen Klasse, in der lokale Version der für die implementierte Schnittstelle benötigten Methoden implementiert werden.
- Wenn zu erwarten ist, daß spezialisierte Versionen des abstrakten Datentyps benötigt werden, so ist eine Modellierung als eine Klasse vorteilhaft, weil dann für dieser einen Klassen eine Unterklasse implementiert werden kann.
Wir werden im Folgenden für unsere Bäume die Modellierung mit einer
Klasse bevorzugen und anschließend spezialisierte Baumtypen von dieser
einen Klasse ableiten.
3.1.3 Implementierung
Für unsere Umsetzung von Bäumen benutzen wir die Modellierung in einer
Klasse. Wir schreiben die Klasse Tree entsprechend unserer
Spezifikation. Zusätzlich sehen wir zwei weitere Konstruktoren vor,
die jeweils einen Standardwert für die beiden Felder setzen:
- Tree(List children): als Knotenmarkierung wird null genommen.
- Tree(a mark): für die Kinder wird eine leere Liste erzeugt.
Wir erhalten folgende einfache Klasse:
Tree
package name.panitz.data.tree;
import java.util.List;
import java.util.Iterator;
import java.util.Enumeration;
import java.util.ArrayList;
import javax.swing.tree.TreeNode;
public class Tree<a> implements TreeNode{
private a mrk;
private List<Tree<a>> chldrn;
Die beiden Felder werden durch den Konstruktor gesetzt:
public Tree(a mark,List<Tree<a>> children){
this.mrk=mark;
this.chldrn=children;
}
Zwei weitere Konstruktoren setzen beziehen sich auf diesen Konstruktor:
Tree
public Tree(List<Tree<a>> children){
this(null,children);
}
public Tree(a mark){
this(mark,new ArrayList<Tree<a>>());
}
public List<Tree<a>> theChildren(){return chldrn;}
public a mark(){return mrk;}
public boolean isLeaf(){return theChildren().isEmpty();}
Aufgabe 9
Erzeugen Sie ein Baumobjekt, das einen Stammbaum Ihrer
Familie darstellt. Die Knoten und Blätter sind mit Namen markiert. Die
Wurzel ist mit Ihren Namen markiert.
Kinderknoten sind mit den leiblichen Eltern der
Person eines Knotens markiert.
3.2 Algorithmen auf Bäumen
Die Selektormethoden für Bäume und Listen können wir jetzt gemeinsam
nutzen, um einfache Algorithmen auf Bäumen umzusetzen.
3.2.1 Knotenanzahl
Entsprechend der Methode length, wie wir sie für Listen
geschrieben haben, lassen sich die Knoten eines Baumes zählen.
Tree
if (theChildren().isEmpty()) return 1
public int count(){
int result = 1; // Startwert 1 für diesen Knoten
//für jedes Kind
for (Tree<a> child: theChildren())
//addiere die Knotenanzahl des Kindes zum Ergebnis
result=result+child.count();
return result;
}
Diese Methode ist rekursiv geschrieben. Der terminierende Fall
versteckt sich dieses mal in der for-Schleife. Wenn die
Liste der Kinder leer ist, so wird die for-Schleife nicht
durchlaufen. Nur im Rumpf der Schleife steht ein rekursiver
Aufruf. Daher gibt es keine Anweisung der Form:if (theChildren().isEmpty()) return 1
3.2.2 toString
Unter Benutzung der Methode toString aus der
Listenimplementierung, läßt sich relativ einfach
eine toString-Methode für unsere Baumimplementierung
umsetzen.
public String toString(){
//Nimm erst die Markierung an diesem Knoten
String result = mark().toString();
//Gibt es keine Kinder, dann bist du fertig
if (isLeaf()) return result;
//ansonsten nimm implizit durch Operator + das
//toString() der Kinder
return result+theChildren();
}
Auch wenn wir es nicht sehen, ist diese Methode rekursiv. Der
Ausdruck result+theChildren() führt dazu, daß auf einer Liste
von Bäumen die Methode toString() ausgeführt wird. Dieses
führt wiederum zur Ausführung der toString-Methode auf
jedes Element und dieses sind wiederum Bäume. Der Aufruf
von toString der Klasse Tree führt über den Umweg
der Methode toString der
Schnittstelle List abermals zur Ausführung
der ToString-Methode aus Tree. Man spricht dabei
auch von verschränkter Rekursion.
3.2.3 Linearisieren
Die Methode flatten erzeugt eine Liste, die die Markierung
jedes Baumknotens genau einmal enthält. Aus einem Baum wird also eine
Liste erzeugt. Die logische Struktur des Baumes wird flachgeklopft.
Tree
public List<a> flatten(){
//leere Liste für das Ergebnis
List<a> result = new ArrayList<a>();
//füge die Markierung dieses Knotens zur
//Ergebnisliste hinzu
result.add(mark());
//für jedes Kind
for (Tree<a> child : theChildren())
//erzeuge dessen Knotenliste und füge alle deren
//Elemente zum Ergebnis hinzu
result.addAll(child.flatten());
return result;
}
Als Ergebnisliste wird ein Objekt der
Klasse ArrayList angelegt. Diesem Objekt wird die Markierung
des aktuellen Knotens zugefügt und dann die Linearisierung jedes der
Kinder. Die Methode addAll aus der
Schnittstelle List sorgt dafür, daß alle Elemente der
Parameterliste hinzugefügt werden.
Aufgabe 10
Testen Sie die in diesem Abschnitt entwickelten Methoden auf
Bäumen mit dem in der letzten Aufgabe erzeugten Baumobjekt.
Aufgabe 11
Punkteaufgabe (4 Punkte):
Für diese Aufgabe gibt es maximal 4 auf die Klausur anzurechnende Punkte. Abgabetermin: wird noch bekanntgegeben.
Für diese Aufgabe gibt es maximal 4 auf die Klausur anzurechnende Punkte. Abgabetermin: wird noch bekanntgegeben.
Schreiben Sie die folgenden weiteren Methoden für die
Klasse Tree. Schreiben Sie Tests für diese Methoden.
{\bf \alph{unteraufgabe})} List leaves(): erzeugt eine Liste der Markierungen an den Blättern des Baumes.
{\bf \alph{unteraufgabe})} String show(): erzeugt eine textuelle Darstellung des Baumes. Jeder Knoten soll eine eigene Zeile haben. Kinderknoten sollen gegenüber einem Elternknoten eingerückt sein.
Beispiel:
william
charles
elizabeth
phillip
diana
spencer
Tipp: Benutzen Sie eine Hilfsmethode
String showAux(String prefix),
die den String prefix vor den erzeugten Zeichenketten anhängt.
{\bf \alph{unteraufgabe})} boolean contains(a o): ist wahr, wenn eine Knotenmarkierung gleich dem Objekt o ist.
{\bf \alph{unteraufgabe})} int maxDepth(): gibt die Länge des längsten Pfades von der Wurzel zu einem Blatt an.
{\bf \alph{unteraufgabe})} List<a> getPath(a o): gibt die Markierungen auf dem Pfad von der Wurzel zu dem Knoten, der mit dem Objekt o markiert ist, zurück. Ergebnis ist eine leere Liste, wenn ein Objekt gleich o nicht existiert.
{\bf \alph{unteraufgabe})} java.util.Iterator<a> iterator(): erzeugt ein Iterator über alle Knotenmarkierungen des Baumes.
Tipp: Benutzen Sie bei der Umsetzung die Methode flatten.
{\bf \alph{unteraufgabe})} public boolean equals(Object other): soll genau dann wahr sein, wenn other ein Baum ist, der die gleiche Struktur und die gleichen Markierungen hat.
{\bf \alph{unteraufgabe})} <b>boolean sameStructure(Tree<a> other): soll genau dann wahr sein, wenn der Baum other die gleiche Struktur hat. Die Markierungen der Knoten können hingegen unterschiedlich sein.
String showAux(String prefix),
die den String prefix vor den erzeugten Zeichenketten anhängt.
{\bf \alph{unteraufgabe})} boolean contains(a o): ist wahr, wenn eine Knotenmarkierung gleich dem Objekt o ist.
{\bf \alph{unteraufgabe})} int maxDepth(): gibt die Länge des längsten Pfades von der Wurzel zu einem Blatt an.
{\bf \alph{unteraufgabe})} List<a> getPath(a o): gibt die Markierungen auf dem Pfad von der Wurzel zu dem Knoten, der mit dem Objekt o markiert ist, zurück. Ergebnis ist eine leere Liste, wenn ein Objekt gleich o nicht existiert.
{\bf \alph{unteraufgabe})} java.util.Iterator<a> iterator(): erzeugt ein Iterator über alle Knotenmarkierungen des Baumes.
Tipp: Benutzen Sie bei der Umsetzung die Methode flatten.
{\bf \alph{unteraufgabe})} public boolean equals(Object other): soll genau dann wahr sein, wenn other ein Baum ist, der die gleiche Struktur und die gleichen Markierungen hat.
{\bf \alph{unteraufgabe})} <b>boolean sameStructure(Tree<a> other): soll genau dann wahr sein, wenn der Baum other die gleiche Struktur hat. Die Markierungen der Knoten können hingegen unterschiedlich sein.
3.2.4 Eltern und Geschwister
Wir können in unserer Implementierung von einem Knoten nicht mehr
seinen Eltern- und seine Geschwisterknoten
angeben. Wir können nur einen Baum von der Wurzel an zu den Blätter
durchlaufen, aber nicht umgekehrt, von einem beliebiegen Knoten zurück
zur Wurzel laufen. Dieses liegt daran, daß wir keinerlei Verbindung
von einem Kind zu seinem Elternknoten haben. Wenn wir eine solche
haben wollen, müssen wir hierfür ein Feld vorsehen. Wir ergänzen
die Klasse Tree somit um ein weiteres Feld.
Tree
public Tree<a> parent=null;
Für einen neuen Baumknoten, der neu erzeugt wird, ist das Feld auf den
Elternknoten zunächst auf null gesetzt. Erst wenn ein
Baumknoten als Kind in einen Baum eingehängt wird, ist sein Feld für
den Elternknoten auf den entsprechenden Baum zu setzen:
Tree
public Tree(a mark,List<Tree<a>> children){
//setze die entsprechenden Felder des Knotens
this.mrk=mark;
this.chldrn=children;
//es gibt noch keinen Elternknoten
this.parent=null;
//setze den neuen Knoten als Elternknoten der Kinder
respectParents();
}
public void respectParents(){
//für jedes Kind
for (Tree<a> child:theChildren()){
// ist dieser Knoten jetzt der Elternknoten
child.parent=this;
}
}
Jetzt haben wir allerdings eine neue Situation. Bisher konnten wir Baumknoten
mehrfach in einen Baum einhängen oder einen Knoten in mehrere Mäume
einhängen. Das geht jetzt nicht mehr. Zwei Bäume können sich nicht mehr
einen Knoten teilen, denn der Knoten kann ja nur einen Elternknoten
speichern. Wir modifizieren jedesmal das Feld parent, wenn wir
einen Knoten als Kinderknoten einen neuen Baumknoten übergeben.
Aufgabe 12
Schreiben Sie eine Methode List<Tree<a>> siblings(),
die die Geschwister eines Knotens
als Liste ausgibt. In dieser Liste der Geschwister soll der Knoten
selbst nicht auftauchen.
3.2.5 Modifizierende Methoden
Bisher haben wir eine rein funktionale Umsetzung von
Bäumen erarbeitet. Einmal erzeugte Bäume sind unveränderbar.
Die einzige Ausnahme war hierbei das Feld parent, das geändert wurde,
sobald ein Knoten in einen Baum eingehängt wurde.
Die
Felder der Klasse Tree sind privat. Es gibt keine Methoden,
die sie verändern. Ebenso war auch unsere Listenimplementierung
gehalten. Die Java Standardsammlumgsklassen haben im Gegensatz dazu
Methoden, die ein Listenobjekt verändern.
Wir können für unsere Klasse Tree auch solche modifizierenden
Methoden implementieren. Solche Methoden fügen typischer Weise einen
neuen Knoten in einen Baum ein oder löschen Knoten. Da es
modifizierende Methoden sind, empfiehlt es sich, sie
als void-Methoden zu schreiben.
addChild
Wir schreiben eine Methode, die an einen Knoten als letztes Kind einen
neuen Knoten einfügt:
Tree
public void addChild(Tree<a> newChild){
List<Tree<a>> chs = theChildren();
newChild.parent=this;
chs.add(newChild);
}
Es wird direkt auf dem Feld mit der Liste der Kinder operiert und die
modifizierende methode add aus der
Schnitstelle List benutzt.
addLeaf
Eine weitere Methode fügt dem Baum ein neues Blatt ein:
Tree
public void addLeaf(a o){addChild(new Tree<a>(o));}
deleteChild
Folgende Methode löscht das n-te Kind aus einem Knoten:
Tree
public void deleteChild(int n){
theChildren().remove(n);
}
In dieser Implementierung wird die modifizierte Liste durch die
Methode theChildren() ermittelt, anstatt auf das
Feld chldrn direkt zuzugreifen.
setMark
Das Feld mrk hat das Attribut private. Wollen wir
seinen Wert aus einem anderen Kontext ändern, so brauchen wir eine
Methode, die dieses macht. Wir können eine
typische Set-Methode schreiben:
Tree
public void setMark(a mark){mrk=mark;}
Beispiel: Baumerzeugung mit modifizierenden Methoden
SkriptTree
package name.panitz.data.tree.example;
import name.panitz.data.tree.Tree;
public class SkriptTree{
public static Tree<String> getSkript(){
Tree<String> skript = new Tree<String>("Programmieren 2");
Tree<String> kap1=new Tree<String>("Frühe und späte Bindung");
Tree<String> kap2
= new Tree<String>
("Graphische Benutzeroberflächen und Graphiken");
Tree<String> kap3
= new Tree<String>("Abstrakte Datentypen");
skript.addChild(kap1);
skript.addChild(kap2);
skript.addChild(kap3);
kap1.addLeaf("Wiederholung: Das Prinzip der späten Bindung");
kap1.addLeaf("Keine späte Bindung für Felder");
kap1.addLeaf("Keine Späte Bindung für überladene Methoden");
Tree<String> sec2_1
= new Tree<String>("Graphische Benutzeroberflächen");
Tree<String> sec2_2
= new Tree<String>("Exkurs: verschachtelte Klassen");
Tree<String> sec2_3
=new Tree<String>("Selbstdefinierte graphische Komponenten");
Tree<String> sec2_4
= new Tree<String>("Weitere Komponente und Ereignisse");
Tree<String> sec2_5
= new Tree<String>("Swing und Steuerfäden");
kap2.addChild(sec2_1);kap2.addChild(sec2_2);
kap2.addChild(sec2_3);kap2.addChild(sec2_4);
kap2.addChild(sec2_5);
Tree<String> sec3_1
= new Tree<String>("Bäume");
Tree<String> sec3_2
= new Tree<String>("Algorithmen auf Bäumen");
Tree<String> sec3_3
= new Tree<String>("Binärbäume");
Tree<String> sec3_4
= new Tree<String>("Binäre Suchbäume");
Tree<String> sec3_5
= new Tree<String>("XML-Dokumente als Bäume");
Tree<String> sec3_6
= new Tree<String>("Keller");
kap3.addChild(sec3_1);kap3.addChild(sec3_2);
kap3.addChild(sec3_3);kap3.addChild(sec3_4);
kap3.addChild(sec3_5);kap3.addChild(sec3_6);
sec2_1.addLeaf("Graphische Komponenten");
sec2_1.addLeaf("Ereignisbehandlung");
sec2_1.addLeaf("Setzen des Layouts");
sec2_2.addLeaf("Innere Klassen");
sec2_2.addLeaf("Anonyme Klassen");
sec2_2.addLeaf("Statisch verschachtelte Klassen");
sec2_3.addLeaf("Graphics Objekte");
sec2_3.addLeaf("Dimensionen");
sec2_3.addLeaf("Farben");
sec2_3.addLeaf("Fonts und ihre Metrik");
sec2_3.addLeaf("Erzeugen graphischer Dateien");
sec2_3.addLeaf("Graphics2D");
sec2_4.addLeaf("Mausereignisse");
sec2_4.addLeaf("Fensterereignisse");
sec2_4.addLeaf("Weitere Komponenten");
sec2_5.addLeaf("Timer in Swing");
sec2_5.addLeaf
("SwingWorker für Steuerfäden in der Ereignisbehandlung");
return skript;
}
}
Aufgabe 13
Schreiben Sie eine modifizierende
Methode
void deleteChildNode(int n),
die den n-ten Kindknoten löscht, und stattdessen die Kinder des n-ten Kindknotens als neue Kinder mit einhängt.
Beispiel:
Wir haben uns in dieser Vorlesung ausgiebig mit Bäumen beschäftigt,
sie aber bisher nicht graphisch sondern lediglich textuell
dargestellt. In diesem Kapitel sollen zwei Möglichkeiten zur
graphischen Darstellung von Bäumen in Java untersucht werden.
Zunächst benutzen wir eine bereits in der swing-Bibliothek
angebotene Komponente zur Baumdarstellung, anschließend definieren wir
eine eigene neue Komponente zur Baumdarstellung.
void deleteChildNode(int n),
die den n-ten Kindknoten löscht, und stattdessen die Kinder des n-ten Kindknotens als neue Kinder mit einhängt.
Beispiel:
a
/ \
/ \
b c
/ \ / \
d e f g
/|\
h i j
|
| wird durch deleteChildNode(1) zu: |
|
3.2.6 Bäume mit JTree graphisch darstellen |
Im Paket javax.swing gibt es eine Klasse, die es erlaubt
beliebige Baumstrukturen graphisch darzustellen, die
Klasse JTree. Diese Klasse übernimmt die graphische
Darstellung eines Baumes. Der darzustellende Baum ist dieser Klasse zu
übergeben. Hierzu hat sie einen Konstruktor, der einen Baum
erhält: JTree(TreeNode root).
Um entsprechend die Klasse JTree benutzen zu können, so daß
sie uns einen Baum darstellt, müssen wir einen Baum, der die
Schnittstelle javax.swing.tree.TreeNode implementiert, zur
Verfügung stellen. Diese Schnittstelle hat 7 relativ naheliegende
Methoden, die sich in ähnlicher Form fast alle in unserer
Klasse Tree auch schon befinden:
package javax.swing.tree;
interface TreeNode{
Enumeration children();
int getChildCount();
TreeNode getParent();
boolean isLeaf();
TreeNode getChildAt(int childIndex);
boolean getAllowsChildren();
int getIndex(TreeNode node);
}
Wir können unsere Klasse Tree entsprechend modifizieren,
damit sie diese Schnittstelle implementiert. Hierzu fügen wir
Implementierungen der in der Schnittstelle verlangten Methoden der
Klasse Tree hinzu und sorgen so dafür, daß unsere Bäume alle
Eigenschaften haben, so daß die Klasse JTree sie graphisch
darstellen können.
public class Tree<a>implements TreeNode{
Entscheidend ist natürlich die Methode children, die inhaltlich
unserer Methode theChildren entspricht.
Leider benutzt die
Schnittstelle als Rückgabetyp eine weitere Klasse aus dem
Paket java.util. Dieses ist die
Schnittstelle Enumeration. Logisch ist sie fast
funktionsgleich mit der Schnittstelle Iterator. Die Existenz
dieser zwei sehr ähnlichen Schnittstellen hat historische Gründe. Mit
einer anonymen inneren Klassen können wir recht einfach ein
Rückgabeobjekt der Schnittstelle erzeugen.
Tree
public Enumeration<TreeNode> children() {
final Iterator<Tree<a>> it = theChildren().iterator();
return new Enumeration<TreeNode>(){
public boolean hasMoreElements(){return it.hasNext();}
public Tree<a> nextElement() {return it.next();}
};
}
Die Methoden getChildCount, getParent, isLeaf getChildAt existieren bereits
oder sind einfach aus der bestehenden Klasse ableitbar.
Tree
public TreeNode getChildAt(int childIndex) {
return theChildren().get(childIndex);
}
public int getChildCount(){return theChildren().size();}
public TreeNode getParent(){return parent;}
Die übrigen zwei Methoden aus der
Schnittstelle TreeNode sind für unsere Zwecke
unerheblich. Wir implementieren sie so, daß sie eine Ausnahme werfen.
Tree
public boolean getAllowsChildren(){
throw new UnsupportedOperationException();
}
public int getIndex(TreeNode node) {
throw new UnsupportedOperationException();
}
Schließlich ändern wir die Methode toString so ab, daß sie
nicht mehr eine String-Repräsentation des ganzen Baumes
ausgibt, sondern nur des aktuellen Knotens:
Tree
public String toString(){return mark().toString();}
Somit haben wir unsere Klasse Tree soweit
massiert, daß sie
von der Klasse JTree als Baummodell genutzt werden kann.
Beispiel:
Wir können jetzt ein beliebiges Objekt der Klasse Tree der Klasse JTree übergeben, um es graphisch darzustellen. Der Code hierzu ist denkbar einfach.
JTreeTest
package name.panitz.data.tree.example;
import javax.swing.JFrame;
import javax.swing.JTree;
public class JTreeTest {
public static void main(String [] args){
JFrame frame = new JFrame("Baumtest Fenster");
frame.getContentPane()
.add(new JTree(SkriptTree.getSkript()));
frame.pack();
frame.setVisible(true);
}
}
Diese Methode erzeugt die graphische Baumdarstellung aus
Abbildung 3.3.
Dieser Baum reagiert dabei sogar auf Mausaktionen, in dem durch
Klicken auf Baumknoten deren Kinder ein- und ausgeblendet werden
können.
Die Klasse JTree verfügt noch über eine große Anzahl weiterer
Funktionalitäten, die wir hier nicht im Detail betrachten wollen.
3.2.7 Bäume zeichnen
Im letzem Unterkapitel haben wir eine fertige Swingkomponente benutzt um Bäume
darzustellen. In diesem Abschnitt werden wir eine eigene Komponente schreiben,
die Bäume graphisch darstellt. Dabei soll ein Baum in der Weise gezeichnet
werden, wir wir es handschriftlich gerne machen: oben zentriert liegt die
Wurzel und Linien führen zu den weiter unten hingeschriebenen Kindern.
Die Hauptschwierigkeit hierbei wird sein, die einzelnen Positionen der
Baumknoten zu berechnen.
DisplayTree
package name.panitz.data.tree;
import java.util.Enumeration;
import javax.swing.JComponent;
import javax.swing.JPanel;
import javax.swing.tree.TreeNode;
import java.awt.Font;
import java.awt.FontMetrics;
import java.awt.Color;
import java.awt.Graphics;
import java.awt.Dimension;
public class DisplayTree extends JPanel{
Ähnlich wie in der Klasse JTree enthält das Objekt, das einen
Baum graphisch darstellt, ein Baummodell:
DisplayTree
private TreeNode treeModell;In zwei Konstanten sei spezifiziert, wieviel Zwischenraum horizontal zwischen Geschwistern und vertikal zwischen Eltern und Kindern liegen soll.
DisplayTree
static final public int VERTICAL_SPACE = 50; static final public int HORIZONTAL_SPACE = 20;In einem Feld werden wir uns die Maße des benutzten Fonts vermerken. Dieses ist wichtig, um die Größe eines Baumknotens zu errechnen.
DisplayTree
private FontMetrics fontMetrics = null;Die Felder für Höhe und Breite werden die Maße der Baumzeichnung wiederspiegeln.
DisplayTree
private int height=0; private int width=0;Diese Maße sind zu berechnen, abhängig vom Font der benutzt wird. Eine bool'scher Wert wird uns jeweils angeben, ob die Maße bereits berechnet wurden.
DisplayTree
private boolean dimensionCalculated = false;Es folgen zwei naheliegende Konstruktoren.
DisplayTree
public DisplayTree(TreeNode tree){treeModell=tree;}
public DisplayTree(TreeNode t,FontMetrics fm){
treeModell=t;fontMetrics=fm;
}
Die schwierigste Methode berechnet, wie groß der zu
zeichnende Baum wird:
DisplayTree
private void calculateDimension(){
Zunächst stellen wir sicher, daß die Fontmaße bekannt sind:
DisplayTree
if (fontMetrics==null){
final Font font = getFont();
fontMetrics = getFontMetrics(font);
}
Die Breite der Knotenmarkierung wird berechnet. Dieses ist die
minimale Breite des Gesamtbaums. Zunächst berechnen wir die Breite
des Wurzelknotens:
DisplayTree
final int x
= fontMetrics.stringWidth(treeModell.toString());
Für jedes Kind berechnen wir nun die Breite und Höhe. Die maximale
Höhe der Kinder bestimmt die Höhe des Gesamtbaums, die Summe aller
Breiten der Kinder, bestimmt die Breite des Gesamtbaums.
DisplayTree
final Dimension childrenDim = childrenSize();
final int childrenX = (int)childrenDim.getWidth();
final int childrenY = (int)childrenDim.getHeight();
Mit der Höhe und Breite der Kinder, läßt sich die Höhe und Breite des
Gesamtbaums berechnen:
DisplayTree
width=x>childrenX?x:childrenX;
height
= childrenY == 0
?fontMetrics.getHeight()
:VERTICAL_SPACE+childrenY;
dimensionCalculated = true;
}
Zum Berechnen der Größe aller Kinder haben wir oben eine Methode
angenommen, die wir hier implementieren.
DisplayTree
Dimension childrenSize(){
int x = 0;
int y = 0;
final Enumeration<TreeNode> it=treeModell.children();
while (it.hasMoreElements()){
final DisplayTree t
= new DisplayTree(it.nextElement(),fontMetrics);
y = y > t.getHeight()?y:t.getHeight();
x=x+t.getWidth();
if (it.hasMoreElements()) x=x+HORIZONTAL_SPACE;
}
return new Dimension(x,y);
}
Mehrere Methoden geben die entsprechende Größe aus, nachdem sie
gegebenenfalls vorher ihre Berechnung angestoßen haben:
DisplayTree
public int getHeight(){
if (!dimensionCalculated) calculateDimension();
return height;
}
public int getWidth(){
if (!dimensionCalculated) calculateDimension();
return width;
}
public Dimension getSize(){
if (!dimensionCalculated) calculateDimension();
return new Dimension(width,height);
}
public Dimension getMinimumSize(){
return getSize();
}
public Dimension getPreferredSize(){
return getSize();
}
Schließlich die eigentliche Methode zum Zeichnen des Baumes. Hierbei
benutzen wir eine Hilfsmethode, die den Baum an eine bestimmte
Position auf der Leinwand plaziert:
DisplayTree
public void paintComponent(Graphics g){paintAt(g,0,0);}
public void paintAt(Graphics g,int x,int y){
fontMetrics = g.getFontMetrics();
final String marks =treeModell.toString();
Zunächst zeichne die Baummarkierung für die Wurzel des
Knotens. Zentriere diese in bezug auf die Breite des zu
zeichnenden Baumes:
DisplayTree
g.drawString
(marks
,x+(getWidth()/2-fontMetrics.stringWidth(marks)/2)
,y+10);
Jetzt sind die Kinder zu zeichenen. Hierzu ist zu berechnen, wo ein
Kind zu positionieren ist. Zusätzlich ist die Kante von
Elternknoten zu Kind zu zeichnen. Hierzu merken wir uns den
Startpunkt der Kanten beim Elternknoten. Auch dieser ist auf der
Breite zentriert:
DisplayTree
final int startLineX = x+getWidth()/2;
final int startLineY = y+10;
Für jedes Kind ist jetzt die x-Position zu berechnen, das Kind zu
zeichnen, und die Kante zum Kind zu zeichenen:
DisplayTree
final Enumeration it=treeModell.children();
final int childrenWidth = (int)childrenSize().getWidth();
//wieviel nach rechts zu rücken ist
int newX
= getWidth()>childrenWidth?(getWidth()-childrenWidth)/2:0;
//die y-Koordinate der Kinder
final int nextY = y+VERTICAL_SPACE;
while (it.hasMoreElements()){
DisplayTree t
= new DisplayTree((TreeNode)it.nextElement());
//x-Positionen für das nächste Kind
final int nextX = x+newX;
//zeichne das Kind
t.paintAt(g,nextX,nextY);
//zeichne Kante
g.drawLine(startLineX,startLineY
,nextX+t.getWidth()/2,nextY);
newX = newX+t.getWidth()+HORIZONTAL_SPACE;
}
}
}
Damit ist die Klasse zur graphischen Darstellung von Bäumen komplett
spezifiziert.
Folgendes kleine Programm benutzt unsere
Klasse DisplayTree in der gleichen Weise, wie wir auch die
Klasse JTree benutzt haben. Das optische Ergebnis ist in
Abbildung 3.4 zu bewundern.
DisplayTreeTest
package name.panitz.data.tree.example;
import name.panitz.data.tree.DisplayTree;
import javax.swing.JFrame;
import javax.swing.JScrollPane;
class DisplayTreeTest {
public static void main(String [] args){
JFrame frame = new JFrame("Baum Fenster");
frame.getContentPane()
.add(new JScrollPane(
new DisplayTree(SkriptTree.getSkript())));
frame.pack();
frame.setVisible(true);
}
}
Wir schreiben eine kleine Klasse mit Methoden, um das Bild eines Baumes in eine
Datei zu speichern.
Zunächst brauchen wir eine ganze Reihe von Klassen, die wir importieren:
TreeToFile
package name.panitz.data.tree;
import name.panitz.gui.graphicsFile.ComponentToFile;
import static name.panitz.gui.graphicsFile.ComponentToFile.*;
import java.io.File;
import java.io.IOException;
import javax.imageio.ImageIO;
import javax.swing.JComponent;
import java.awt.image.RenderedImage;
public class TreeToFile{
public static void treeToFile(Tree tree,String fileName){
try {
final JComponent component = new DisplayTree(tree);
final RenderedImage image = createComponentImage(component);
ImageIO.write(image,"png", new File(fileName+".png"));
ImageIO.write(image,"jpg", new File(fileName+".jpg"));
}catch (IOException e) {System.out.println(e);}
}
}
3.3 Binärbäume
Listen sind Bäume, in denen jeder Knoten maximal ein Kind
hat. Binärbäume sind Bäume, in denen jeder Knoten maximal zwei Kinder
hat. Wir können eine Unterklasse von Tree schreiben, in der
ein Konstruktor sicherstellt, daß ein Knoten maximal zwei Kinder hat.
Wir wollen zusätzlich zulassen, daß es ein rechtes aber kein linkes
Kind gibt. Dafür stellen wir zwei Felder zur Verfügung, die die
entsprechenden Kinder enthalten. Existiert ein Kind nicht, so sei das
entsprechende Feld mit null belegt.
Damit wir die geerbten Methoden fehlerfrei benutzen können, müssen wir
sicherstellen, daß die Methode children auch für diese
Unterklasse gemäß der Spezifikation funktioniert.
BinTree
package name.panitz.data.tree;
import java.util.List;
import java.util.ArrayList;
public class BinTree<a> extends Tree<a>{
//private Felder für rechtes und linkes Kind
private BinTree<a> rght;
private BinTree<a> lft;
Wir sehen zwei naheliegende Konstuktoren vor:
BinTree
public BinTree(BinTree<a> left,a mark,BinTree<a> right){
super(mark);lft=left; rght=right;}
public BinTree(a mark){this(null,mark,null);}
Zwei Selektormethoden greifen auf das linken bzw.
rechte Kind zu:
BinTree
public BinTree<a> left(){return lft;}
public BinTree<a> right(){return rght;}
Wir müssen die Methode theChildren überschreiben. Die Kinder
befinden sich nicht mehr in einer Liste gespeichert sondern in den
zwei speziellen hierfür angelegten Feldern:
BinTree
public List<Tree<a>> theChildren(){
List<Tree<a>> result = new ArrayList<Tree<a>>();
if (left()!=null) result.add(left());
if (right()!=null) result.add(right());
return result;
}
3.3.1 Probleme der Klasse BinTree
Als Unterklasse der Klasse Tree erben wir sämtliche Methoden
der Klasse Tree. Das ist zunächst einmal positiv, weil wir
automatisch Methoden wie count oder flatten erben
und nicht
neu zu implementieren brauchen.
Leider spielen uns die modifizierenden Methoden der
Klasse Tree dabei einen Streich. Kurz gesagt: sie
funktionieren nicht für die Klasse BinTree. Sie modifizieren
die Liste der Kinder, wie wir sie von der
Methode theChildren() erhalten. Diese Liste ist in der
Klasse BinTree transient, d.h. sie wird nicht
im Objekt direkt gespeichert, sondern jeweils neu aus den beiden
Feldern rght und lft erzeugt. Eine Modifikation an
dieser Liste hat also keinen bleibenden (persistenten) Effekt.
Andererseits ist dieses eine gute Eigenschaft, denn damit wird
verhindet, daß eine modifizierende Methode die Binäreigenschaft
zerstört. Die Methode addChild könnte sonst einen binären
Baum an einem Knoten ein drittes Kind einfügen.
Es empfiehlt sich trotzdem, dieses Problem nicht stillschweigend
hinzunehmen, und eine entsprechende Ausnahme zu werfen. Daher fügen
wir der Klasse BinTree folgende Variante der
Methode addLeaf hinzu:
BinTree
public void addLeaf(a o){
throw new UnsupportedOperationException();
}
Für die Methode deleteChild können wir eine Variante
anbieten, die auf binären Bäumen funktioniert.
BinTree
public void deleteChild(int n){
if (n==0) lft=null;
else if (n==1) rght=null;
else throw new IndexOutOfBoundsException ();
}
Modifizierende Methoden, die ungefährlich für die Binärstrukrur der
Bäume sind, setzen die beiden Kinder eines Baumes neu:
BinTree
void setLeft(BinTree<a> l){ lft=l;}
void setRight(BinTree<a> r){ rght=r;}
Aufgabe 14
Überschreiben Sie die
Methoden addLeaf und deleteChildNode in
der Klasse BinTree, so daß sie nur eine Ausnahme werfen,
wenn die Durchführung der Modifikation dazu führen würde, daß das
Objekt, auf dem die Methode angewendet wird, anschließend kein
Binärbaum mehr wäre.
3.3.2 Linearisieren binärer Bäume
In der Klasse Tree haben wir eine Methode definiert, die die
Knoten eines Baumes in einer linearisierten Form in eine Liste
speichert. Wir haben uns bisher keine Gedanken gemacht, in welcher
Reihenfolge die Baumknoten in der Ergebnisliste stehen. Hierbei sind
mehrere fundamentale Ordnungen der Knoten des Baumes vorstellbar:
Preordnung
Unsere bisherige
Implementierung der Methode flatten benutzt die
Reihenfolge, in der ein Knoten in der
Ergebnisliste immer vor seinen Kindern steht und Geschwisterknoten
stets erst nach den Knoten folgen. Diese Ordnung nennt man Preordnung.
In der Preordnung kommt die Wurzel eines Baumes als erstes Element der
Ergebnisliste.
Postordnung
Wie der Name vermuten läßt, ist die Postordnung gerade der umgekehrte
Weg zur Preordnung. Jeder Knoten steht in der Liste nach allen
Kinderknoten. Die Wurzel wird damit das letzte Element der
Ergebnisliste.
Aufgabe 15
Schreiben Sie analog zur Methode flatten in der
Klasse Tree eine Methode
List<a> postorder(), die die Knoten eines Baumes in Postordnung linearisiert.
List<a> postorder(), die die Knoten eines Baumes in Postordnung linearisiert.
Inordnung
Pre- und Postordnung kann man nicht nur auf Binärbäumen definieren,
sondern allgemein für alle Bäume. Die dritte Variante hingegen, die
Inordnung, kann nur für Binärbäume sinnvoll definiert werden. Hier
steht jeder Knoten nach allen Knoten seines linken Kindes und vor
allen Knoten seines rechten Kindes.
BinTree
public List<a> inorder(){
//Ergebnisliste
List<a> result = new ArrayList<a>();
//gibt es ein linkes Kind, füge dessen
//Linearisierung hinzu
if (left()!=null) result.addAll(left().inorder());
//dann den Knoten selbst
result.add(mark());
//und gegebenenfalls dann das recte Kind
if (right()!=null) result.addAll(right().inorder());
return result;
}
Pre-, Post- und Inordnung entsprechen der Pre-, Post- und
Infixschreibweise von Operatorausdrücken. Betrachtet man einen
Operatorausdruck als Baum mit dem Operator als Wurzel und den beiden
Operanden als Kindern, dann ergibt sich die Analogie sofort.
Militärordnung
Eine Ordnung, die der Baumstruktur sehr entgegen steht, ist die
sogenannte Militärordnung. Diese Ordnung geht ebenenweise
vor. Geschwisterknoten stehen in der Liste direkt
nebeneinander.
Abbildung 3.5 veranschaulicht diese
Ordnung:
Zunächst wird die Wurzel genommen, dann der Reihe nach alle Kinder der
Wurzel, dann die Kinder der Kinder usw. Es werden also alle Knoten
einer Generation hintereinander geschrieben. Diese Ordnung entspricht
nicht der rekursiven Definition einer Baumstruktur. Daher ist ihre
Implementierung auch nicht sehr elegant. Hierfür sind ein paar
Hilfslisten zu verwalten. Eine Liste für die aktuelle Generation und
eine in der die Knoten der nächsten Generation gesammelt werden.
BinTree
public List military(){
//Ergebnisliste enthält erst diesen Knoten
List<a> result=new ArrayList<a>();
result.add(mark());
//Wir speichern uns die Knoten einer
//aktuellen Generation
List<Tree<a>> currentGeneration = theChildren();
//Solange es in der aktuellen Generation Knoten gibt
while (!currentGeneration.isEmpty()){
//erzeuge die nächste Generation
List<Tree<a>> nextGeneration=new ArrayList<Tree<a>>();
for (Tree<a> nextChild:currentGeneration){
nextGeneration.addAll(nextChild.theChildren());
//Füge das Elemente der aktuellen Generation
//zum Ergebnis
result.add(nextChild.mark());
}
//schalte eine Generation tiefer
currentGeneration=nextGeneration;
}
return result;
}}
Aufgabe 16
Rechnen Sie auf dem Papier ein Beispiel für die Arbeitsweise
der Methode military().
3.4 Binäre Suchbäume
Binärbäume können dazu genutzt werden, um Objekte effizient gemäß
einer Ordnung zu speichern und effizient nach ihnen unter Benutzung
dieser Ordnung wieder zu suchen. Die Knotenmarkierungen sollen hierzu
nicht mehr beliebige Objekte sein, sondern Objekte, die die
Schnittstelle Comparable implementieren. Solche Objekte
können mit beliebigen Objekten verglichen werden, so daß sie eine
Ordnungsrelation haben.
Binäre Bäume sollen diese Eigenschaft so ausnutzen, daß für einen
Knoten gilt:
- jede Knotenmarkierung eines linken Teilbaums ist kleiner oder gleich als die Knotenmarkierung.
- jede Knotenmarkierung eines rechten Teilbaums ist größer als die Knotenmarkierung.
Man erkennt, daß die Konstruktion solcher Bäume nicht mehr lokal
geschehen kann, indem der linke und der rechte Teilbaum in einem neuen
Knoten zusammengefasst werden. Bei der Baumkonstruktion ist ein neuer
Knoten entsprechend der Ordnung an der richtige Stelle als Blatt
einzuhängen.
Wir schreiben eine
Unterklasse SearchTree der Klasse BinTree. Diese hat
nur einen Konstruktor, um einen Baum mit nur einem Wurzelknoten zu
konstruieren. Weitere Knoten können mit der Methode insert in
den Baum eingefügt werden. Die Methode insert stellt sicher,
daß der Baum die größer Relation der Elemente berücksichtigt. Die
Elemente des Baumes müssen die
Schnittstelle Comparable implementieren.
SearchTree
package name.panitz.data.tree;
public class SearchTree<a extends Comparable<a>>
extends BinTree<a>{
Wir sehen nur einen Konstruktor vor, der ein Blatt erzeugt
SearchTree
SearchTree(a o){super(o);}
Suchbäume wachsen durch eine modifizierende Einfügeoperation:
SearchTree
public void insert(a o){
if (o.compareTo(mark())<=0){
//neuer Knoten ist kneiner, also in den
//linken Teilbaum
if (left()==null){
setLeft(new SearchTree<a>(o));
}else
((SearchTree<a>)left()).insert(o);
}else{
//wenn der neue Knoten also größer, dann dasselbe
//im rechten Teilbaum
if (right()==null){
setRight(new SearchTree<a>(o));
}else
((SearchTree<a>)right()).insert(o);
}
}
Wir können für interne Zwecke einen Konstruktor vorsehen, der einen
Suchbaum direkt aus den Kindern konstruiert. Hierbei wollen wir uns
aber nicht darauf verlassen, daß dem Konstruktor solche Teilbäume und
eine solche Knotenmarkierung übergeben werden, daß der resultierende
Baum ein korrekter Suchbaum ist.
SearchTree
private SearchTree
(SearchTree<a> l,a o,SearchTree<a> r){
super(l,o,r);
try {
if (!( o.compareTo(l.mark())>=0
&& o.compareTo(r.mark())<=0))
throw new IllegalArgumentException
("ordering violation in search tree construction");
}catch(NullPointerException _){
}
}
Die if-Bedingung mit der Prüfung auf eine Eigenschaft der
Parameter ist ein typischer Fall für eine Zusicherung, wie sie seit
Javas Version 1.4 ein fester Bestandteil von Java ist.
Die Linearisierung eines binären Suchbaums in Inordnung ergibt eine
sortierte Liste der Baumknoten, wie man sich mit folgenden Test
vergegenwärtigen kann:
TestSearchTree
package name.panitz.data.tree;
import javax.swing.*;
public class TestSearchTree {
public static void main(String [] args){
SearchTree<String> t = new SearchTree<String>("otto");
t.insert("sven");
t.insert("eric");
t.insert("lars");
t.insert("uwe");
t.insert("theo");
t.insert("otto");
t.insert("kai");
t.insert("henrik");
t.insert("august");
t.insert("berthold");
t.insert("arthur");
t.insert("arno");
t.insert("william");
t.insert("tibor");
t.insert("hassan");
t.insert("erwin");
t.insert("anna");
System.out.println(t.inorder());
JFrame frame = new JFrame("Baum Fenster");
frame.getContentPane().add(new DisplayTree(t));
frame.pack();
frame.setVisible(true);
}
}
Das Programm führt zu folgender Ausgabe auf der Kommandozeile.
sep@swe10:~/fh/prog2/beispiele/Tree> java TestSearchTree [anna, arno, arthur, august, berthold, eric, erwin, hassan, henrik, kai, lars, otto, otto, sven, theo, tibor, uwe, william] sep@swe10:~/fh/prog2/beispiele/Tree>
Aufgabe 17
Zeichnen Sie schrittweise die Baumstruktur, die im
Programm TestSearchTree aufgebaut wird.
Beweis der Sortiereigenschaft
Wir haben oben behauptet und experiementell an einem Beispiel
ausprobiert, daß die Inordnung eines binären Suchbaums eine
sortierte Liste als Ergebnis hat. Wir wollen jetzt versuchen diese
Aussage zu beweisen.
Zum Beweis einer Aussage über eine rekursiv definierten Datenstruktur
(wie Listen und Bäume) bedient man sich der vollständigen
Induktion.4 Hierbei geht die
Induktion meist über die Größe der Datenobjekte.
Als Induktionsanfang dient das kleinste denkbare Datenobjekt, bei
Listen also leere Listen, bei Bäumen Blätter. Der Induktionsschluß
setzt dabei voraus, daß die Aussage für alle kleineren Objekte bereits
bewiesen ist, also für alle Teilobjekte (Teilbäume und Teillisten)
bereits gilt.
Beweisen wir entsprechend die Aussage, daß die Liste der Elemente eines
binären Suchbaums in Inordnung sortiert ist:
- Anfang: Der Induktionsanfang behauptet, die Inordung eines Blattes ist sortiert. Für ein Blatt k gilt: left(k) = null und right(k) = null. Es folgt, daß die Inordung nur ein Element, nämlich mark(k), enthält. Einelementige Listen sind immer sortiert.
- Schritt: Wir wollen die Aussage beweisen für alle Bäume k mit: count(k)=n.
Annahme: die Aussage ist wahr für alle
Bäume k˘
mit count(k˘) < n.
Die Definition der Inordnung ist:
inorder(k) = (inorder(left(k)),mark(k),inorder(right(k))).
inorder(k) = (inorder(left(k)),mark(k),inorder(right(k))).
Für endliche Bäume gilt:
count(left(k)) < n und count(right(k)) < n
Nach der Induktionsvoraussetzung gilt damit, daß
inorder(left(k)) und inorder(right(k))
sortierte Listen sind.
count(left(k)) < n und count(right(k)) < n
Nach der Induktionsvoraussetzung gilt damit, daß
inorder(left(k)) und inorder(right(k))
sortierte Listen sind.
Über die Definition der binären Suchbäume gilt:
für alle x Î inorder(left(k)) gilt x Ł mark(k)
und für alle x Î inorder(right(k)) gilt x > mark(k)
für alle x Î inorder(left(k)) gilt x Ł mark(k)
und für alle x Î inorder(right(k)) gilt x > mark(k)
Damit ist insbesondere die Liste inorder(k) sortiert.
3.4.1 Suchen in Binärbäumen
Die Sortiereigenschaft der Suchbäume erlaubt es jetzt, die
Methode contains so zu schreiben, daß sie maximal einen Pfad
durchlaufen muß. Es muß nicht mehr der ganze Baum betrachtet werden.
SearchTree
public boolean contains(a o){
//bist du es schon selbst
if (mark().equals(o)) return true;
//links oder rechts suchen:
final int compRes = mark().compareTo(o);
if (compRes>0){
//keine Knoten mehr. Dann ist er nicht enthalten
if (left()==null) return false;
//Sonst such weiter unten im Baum
else return ((SearchTree<a>)left()).contains(o);
}
if (compRes<0){
if (right()==null) return false;
else return ((SearchTree<a>)right()).contains(o);
}
return false;
}
Wie man sieht, ist die Methode in ihrer Struktur analog zur
Methode insert.
3.4.2 Entartete Bäume
Bäume, die keine eigentliche Baumstruktur mehr haben, sondern nur noch
Listen sind, werden manchmal auch als entartete Bäume
bezeichnet. Insbesondere bei binären Suchbäumen verlieren wir die
schönen Eigenschaften, nämlich daß wir maximal in der maximalen
Pfadlänge im Baum zu suchen brauchen.
Aufgabe 18
Erzeugen Sie ein Objekt des typs SearchTree und
fügen Sie nacheinander die folgenden Elemente ein:
"anna","berta","carla","dieter","erwin","florian","gustav"
Lassen Sie anschließend die maximale Tiefe des Baumes ausgeben.
"anna","berta","carla","dieter","erwin","florian","gustav"
Lassen Sie anschließend die maximale Tiefe des Baumes ausgeben.
Balanzieren von Bäumen
Wie wir in der letzten Aufgabe sehen konnnten, liegt es an der
Reihenfolge, in der die Elemente in einem binären Suchbaum eingefügt
werden, wie gut ein Baum ausbalanziert ist. Wir sprechen von
einem ausbalanzierten Baum, wenn sein linker und rechter Teilbaum die
gleiche Tiefe haben.
Man kann einen Baum, der nicht ausbalanziert ist, so verändern, daß er
weiterhin ein korrekter binärer Suchbaum in Bezug auf die Ordnung
ist, aber die Tiefen der linken und rechten Kinder ausgewogen sind,
d.h. sich nicht um mehr als eins unterscheiden.
Spezifikation
Beispiel:
Betrachten Sie den Baum aus Abbildung 3.6
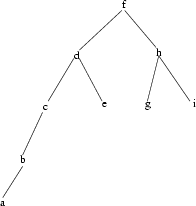
Der linke Teilbaum hat eine Tiefe von 4, der rechte eine Tiefe von
2. Wir können den Baum so verändern, daß beide Kinder eine Tiefe von 3
haben. Wir bekommen den Baum aus
Abbildung 3.7
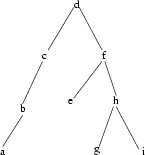
Das linke Kind dieses Baumes ist auch nicht ausbalanziert, wir können
den Baum noch einmal verändern und erhalten den Baum
in Abbildung 3.8:
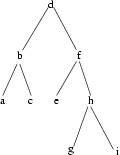
Zum Ausbalanzieren wird ein Baum gedreht. Einer seiner Kinderknoten
wird die neue Wurzel und die alte Wurzel dessen Kind. Es gibt zwei
Richtungen, in die gedreht werden kann: mit und gegen den
Urhzeigersinn. Schematisch lassen sich diese beiden Operationen mit
folgenden Gleichungen spezifizieren:
- rotateRight(Node(Node(l2,x2,r2),x1,r1)) = Node(l2,x2,Node(r2,x1,r1))
- rotateLeft(Node(l1,x1,Node(l2,x2,r2))) = Node(Node(l1,x1,l2),x2,r2)
In graphischer Darstellung wird die erste Gleichung zu:
|
|
|
|
|
Wir können generell zwei Umsetzungen des oben spezifizierten
Algorithmus wählen: eine die einen neues Baumobjekt erzeugt und keinde
der bestehenden Bäume modifiziert und eine, die die Felder der
bestehenden Baumknoten so umändert, daß das Objekt, auf dem die
Methode aufgerufen wird, modifiziert wird.
Funktionale Umsetzung
Für die funktionale Umsetzung können wir eine statische Methode
schreiben. Sie bekommt einen Baum und soll einen neuen Baum, der durch
Rotation aus den Eingabebaum entstanden ist, als Ergebnis liefern.
Die Umsetzung leitet sich direkt aus der Spezifikation über eine
Gleichung ab. Wir benutzen dieselben Bezeichner wie in der
Spezifikation.
SearchTree
public static <a extends Comparable<a>> SearchTree<a>
rotateRight(SearchTree<a> t){
try{
//speichere die einzelnen Teile in die Bezeichner,
//die wir in der Spezifikation benutzt haben
final SearchTree<a> l2 = (SearchTree<a>)t.left().left();
final SearchTree<a> r2 = (SearchTree<a>)t.left().right();
final SearchTree<a> r1 = (SearchTree<a>)t.right();
final a x1 = t.mark();
final a x2 = t.left().mark();
return new SearchTree<a>
(l2,x2,new SearchTree<a>(r2,x1,r1));
}catch (NullPointerException _){
return t;
}
}
Die Ausnahme tritt auf, wenn das linke Kind nicht existiert, also hier
der Wert null steht. Dann kann nicht nach rechts rotiert
werden (da links nichts zum Rotieren steht). In dem Fall, das nicht
rotiert werden kann, wird der Eingabebaum unverändert ausgegeben.
Modifizierende Umsetzung
Wir können die modifizierende Methode zum Rotieren eines Baumes in der
Klasse BinTree implementieren.
Wir benutzen wieder die Bezeichner
aus unserer Spezifikation. Anstatt aber wie eben neue Knoten zu
erzeugen, setzen die entsprechenden Referenzen um.
SearchTree
void rotateRight(){
try{
BinTree<a> l1 = left();
BinTree<a> l2 = l1.left();
BinTree<a> r2 = l1.right();
BinTree<a> r1 = right();
a x1 = mark();
a x2 = l1.mark();
setMark(x2);
setLeft(l2);
setRight(l1);
l1.setMark(x1);
l1.setLeft(r2);
l1.setRight(r1);
}catch (NullPointerException _){
}
}}
Die Ausnahme wird
schon in der zweiten Zeile geworfen, bevor Referenzen verändert
wurden. Das Objekt bleibt unverändert. Ansonsten werden die Knoten
entsprechend der Spezifikation umgehängt.
Aufgabe 19
{\bf \alph{unteraufgabe})} Schreiben sie entsprechend die Methode:
static public SearchTree rotateLeft(SearchTree t)
{\bf \alph{unteraufgabe})}
Schreiben Sie in der Klasse BinTree die
entsprechende modifizierende Methode rotateLeft()
{\bf \alph{unteraufgabe})} Testen Sie die beiden Rotierungsmethoden. Testen Sie, ob die Tiefe der Kinder sich verändert und ob die Inordnung gleich bleibt. Testen Sie insbesondere auch einen Fall, in dem die NullPointerException abgefangen wird.
{\bf \alph{unteraufgabe})} Testen Sie die beiden Rotierungsmethoden. Testen Sie, ob die Tiefe der Kinder sich verändert und ob die Inordnung gleich bleibt. Testen Sie insbesondere auch einen Fall, in dem die NullPointerException abgefangen wird.
Chapter 4
Formale Sprachen, Grammatiken, Parser
Sprachen sind ein fundamentales Konzept nicht nur der Informatik. In
der Informatik begegnen uns als auffälligste Form der SpracheProgrammiersprachen. Es gibt gewisse Regeln, nach denen die Sätze
einen Sprache aus einer Menge von Wörtern geformt werden können.
Die Regeln nennen wir im
allgemeinen eine Grammatik. Ein Satz einer
Programmiersprache nennen wir Programm. Die Wörter sind,
Schlüsselwörter, Bezeichner, Konstanten und Sonderzeichen.
Ausführlich beschäftigt sich die Vorlesung Compilerbau[GKS01] mit
formalen Sprachen. Wir werden in diesem Kapitel die wichtigsten
Grundkenntnisse hierzu betrachten, wie sie zum Handwerkszeug eines
jeden Informatikers gehören.
4.1 formale Sprachen
Eine der bahnbrechenden Erfindungen des 20. Jahrhunderts
geht auf den Sprachwissenschaftler Noam
Chomsky[Cho56]5 zurück. Er
präsentierte als erster ein formales Regelsystem, mit dem die
Grammatik einer Sprache beschrieben werden kann. Dieses Regelsystem
ist in seiner Idee verblüffend einfach. Es bietet Regeln an,
mit denen mechanisch die Sätze einer Sprache generiert werden können.
Systematisch wurden Chomsky Ideen zum erstenmal für die Beschreibung
der Syntax der Programmiersprache Algol angewendet[NB60].
4.1.1 kontextfreie Grammatik
Eine kontextfreie Grammatik besteht aus
- einer Menge T von Wörteren, den Terminalsymbole.
- einer Menge N von Nichtterminalsymbolen.
- ein ausgezeichnetes Startsymbol S Î N.
- einer endlichen Menge  von Regeln der Form:
nt::= t1... tn, wobei nt Î N, ti Î NČT.
Mit den Regeln einer kontextfreien Grammatik werden Sätze gebildet,
indem ausgehend vom Startsymbol Regel angewendet werden. Bei einer
Regelanwendung wird ein Nichtterminalzeichen t durch die Rechte Seite
einer Regel, die t auf der linken Seite hat, ersetzt.
Eine Grammatik beschreibt die Syntax einer Sprache im Gegensatz zur
Semantik, der Bedeutung, einer Sprache.
Beispiel:
Wir geben eine Grammatik an, die einfache Sätze über unser Sonnensystem auf Englisch bilden kann:
- T={mars,mercury,deimos,phoebus,orbits,is,a,moon,planet}
- N={start,noun-phrase,verb-phrase,noun,verb,article}
- S=start
- start ::= noun-phrase verb-phrase
noun-phrase ::= noun
noun-phrase ::= article nounverb-phrase ::= verb noun-phrasenoun ::= planet
noun ::= moon
noun ::= mars
noun ::= deimos
noun ::= phoebusverb ::= orbits
verb ::= isarticle ::= a
Wir können mit dieser Grammatik Sätze in der folgenden Art bilden:
- start
®noun-phrase verb-phrase
®article noun verb-phrase
®article noun verb noun-phrase
® a noun verb noun-phrase
® a moon verb noun-phrase
® a moon orbits noun-phrase
® a moon orbits noun
® a moon orbits mars - start
®noun-phrase verb-phrase
®noun verb-phrase
® mercury verb-phrase
® mercury verb noun-phrase
® mercury is noun-phrase
® mercury is article noun
® mercury is a noun
® mercury is a planet - Mit dieser einfachen Grammatik lassen sich auch Sätze bilden, die weder korrektes Englisch sind, noch eine vernünftige inhaltliche Aussage machen:
start
®noun-phrase verb-phrase
®noun verb-phrase
® planet verb-phrase
® planet verb noun-phrase
® planet orbits noun-phrase
® planet orbits article noun
® planet orbits a noun
® planet orbits a phoebus
®noun-phrase verb-phrase
®noun verb-phrase
® planet verb-phrase
® planet verb noun-phrase
® planet orbits noun-phrase
® planet orbits article noun
® planet orbits a noun
® planet orbits a phoebus
Rekursive Grammatiken
Die Grammatik aus dem letzen Beispiel kann nur endlich viele Sätze
generieren. Will man mit einer Grammatik unendlich viele Sätze
beschreiben, so wie eine Programmiersprache unendlich viele Programme
hat, so kann man sich dem Trick der Rekursion bedienen. Eine Grammatik
kann rekursive Regeln enthalten; das sind Regeln, in denen auf der
rechten Seite das Nichtterminalsymbol der linken Seite wieder
auftaucht.
Aufgabe 20
Erweitern Sie die obige Grammatik so, daß sie mit ihr auch
geklammerte arithmetische Ausdrücke ableiten können. Hierfür gibt es
zwei neue Terminalsymbolde: ( und ).
Beispiel:
Die folgende Grammatik erlaubt es arithmetische Ausdrücke zu generieren:
- T={0,1,2,3,4,5,6,7,8,9,+,-,*,/}
- N={start,expr,op,integer,digit,}
- S=start
- start ::= expr
expr ::= integer
expr ::= integer op exprinteger ::= digitinteger ::= digit integerop ::= +
op ::= -
op ::= *
op ::= /digit ::= 0
digit ::= 1
digit ::= 2
digit ::= 3
digit ::= 4
digit ::= 5
digit ::= 6
digit ::= 7
digit ::= 8
digit ::= 9
Diese Grammatik hat zwei rekursive Regeln: eine für das
Nichtterminal expr und eines für das
Nichtterminal integer.
Folgende Abeleitung generiert einen arithmetischen Ausdrucke mit dieser
Grammatik:
- start
®expr
®integer op expr
®integer op integer op expr
®integer op integer op integer op expr
®integer op integer op integer op integer
®integer + integer op integer op integer
®integer + integer * integer op integer
®integer + integer * integer -integer
®digit integer + integer * integer - integer
® 1 integer + integer * integer - integer
® 1 digit integer + integer *integer - integer
® 12 integer + integer *integer - integer
® 12 digit + integer * integer - integer
® 129+ integer * integer -integer
® 129+ digit * integer -integer
® 129+4* integer - integer
® 129+4* digit integer - integer
® 129+4*5integer - integer
® 129+4*5digit - integer
® 129+4*53- integer
® 129+4*53- digit integer
® 129+4*53-8 integer
® 129+4*53-8 digit
® 129+4*53-87
Schreiben Sie
eine Ableitung für den Ausdruck: 1+(2*20)+1
Grenzen kontextfreier Grammatiken
Kontextfreie Grammatiken sind ein einfaches und dennoch mächtiges
Beschreibungsmittel für Sprachen. Dennoch gibt es viele Sprachen, die
nicht durch eine kontextfreie Grammatik beschrieben werden können.
syntaktische Grenzen
Es gibt syntaktisch recht einfache Sprachen, die sich nicht durch eine
kontextfreie Grammatik beschreiben lassen. Eine sehr einfache solche
Sprache besteht aus drei Wörtern: T={a,b,c}. Die
Sätze dieser Sprache sollen so gebildet sein, daß für eine Zahl n
eine Folge von n mal dem Zeichen a, n mal das Zeichen b und
schließlich n mal das Zeichen c folgt,
also
{anbncn|n Î IN}.
Die Sätze dieser Sprache lassen sich aufzählen:
abc
aabbcc
aaabbbccc
aaaabbbbcccc
aaaaabbbbbccccc
aaaaaabbbbbbcccccc
...
Es gibt formale Beweise, daß derartige Sprachen sich nicht mit
kontextfreie Grammatiken bilden lassen. Versuchen Sie einmal das
Unmögliche: eine Grammatik aufzustellen, die diese Sprache erzeugt.
aabbcc
aaabbbccc
aaaabbbbcccc
aaaaabbbbbccccc
aaaaaabbbbbbcccccc
...
Eine weitere einfache Sprache, die nicht durch eine kontextfreie auszudrücken
ist, hat zwei Terminalsymbole und verlangt, daß in jedem Satz die
beiden Symbole gleich oft vorkommen, die Reihenfolge jedoch beliebig
sein kann.
semantische Grenzen
Über die Syntax hinaus, haben Sprachen noch weitere Einschränkungen,
die sich nicht in der Grammatik ausdrücken lassen. Die meisten
syntaktisch korrekten Javaprogramme werden trotzdem vom Javaübersetzer
als inkorrekt zurückgewiesen. Diese Programme verstoßen gegen
semantische Beschränkungen, wie z.B. gegen die
Zuweisungskompatibilität. Das Programm:
class SemanticalIncorrect{int i = "1";}
ist syntaktisch nach den Regeln der Javagrammatik korrekt gebildet,
verletzt aber die Beschränkung, daß einem Feld vom
Typ int kein Objekt des Typs String zugewiesen
werden darf.
Aus diesen Grund besteht ein Übersetzer aus zwei großen Teilen. Der
syntaktischen Analyse, die prüft, ob der Satz mit den Regeln der
Grammatik erzeugt werden kann und der semantischen Analyse, die
anschließend zusätzliche semantische Bedingungen prüft.
Das leere Wort
Manchmal will man in einer Grammatik ausdrücken, daß in
Nichtterminalsymbol auch zu einem leeren Folge von Symbolen reduzieren
soll. Hierzu könnte man die Regel
t::=mit leerer rechter Seite schreiben. Es ist eine Konvention ein spezielles Zeichen für das leere Wort zu benutzen. Hierzu bedient man sich des griechischen Buchtstabens e. Obige Regel würde man also schreiben als:
t::=e
Lexikalische Struktur
Bisher haben wir uns keine Gedanken gemacht, woher die Wörter unserer
Sprache kommen. Wir haben bisher immer eine gegebene Menge
angenommen. Die Wörter einer Sprache bestimmen ihre lexikalische
Struktur. In unseren obigen Beispielen haben wir sehr unterschiedliche
Arten von Wörtern: einmal Wörter der englischen Sprache und einmal
Ziffernsymbole und arithmetische Operatorsymbole. Im Kontext von
Programmiersprachen spricht man von Token.
Bevor wir testen können, ob ein Satz mit einer Grammatik erzeugt
werden kann, sind die einzelnen Wörter in diesem Satz zu
identifizieren. Dieses geschieht in einer lexikalischen Analyse. Man
spricht auch vom Lexer und Tokenizer. Um zu
beschreiben, wie die einzelnen lexikalischen Einheiten einer Sprache
aussehen, bedient man sich eines weiteren Formalismus, den regulären
Ausdrücken.
Andere Grammatiken
Die in diesem Kapitel vorgestellten Grammatiken
heißen kontextfrei, weil eine Regel für ein
Nichtterminalzeichen angewendet wird, ohne dabei zu betrachten, was
vor oder nach dem Zeichen für ein weiteres Zeichen steht, der Kontext
also nicht betrachtet wird. Läßt man auch Regeln zu, die auf der
linken Seite nicht ein Nichtterminalzeichen stehen haben, so kann man
mächtigere Sprachen beschreiben, als mit einer kontextfreien
Grammatik.
Beispiel:
Wir können mit der folgenden nicht-kontextfreien Grammatik die Sprache beschreiben, in der jeder Satz gleich oft die beiden Terminalsymbole, eber in beliebiger Reihenfolge enthält.
- T={a,b}
- N={start,A,B}
- S=start
- start ::= ABstart
start ::= eAB ::= BABA ::= ABA ::= aB ::= bstart
®ABstart
®ABABstart
®ABABABstart
®ABABABABstart
®ABABABABABstart
®ABABABABAB
®AABBABABAB
®AABBBAABAB
®AABBBABAAB
®AABBBABABA
®AABBBABBAA
®AABBBBABAA
®AABBBBBAAA
® aABBBBBAAA
® aaBBBBBAAA
® aabBBBBAAA
® aabbBBBAAA
® aabbbBBAAA
® aabbbbBAAA
® aabbbbbAAA
® aabbbbbaAA
® aabbbbbaaA
® aabbbbbaaa
Beispiel:
Auch die nicht durch eine kontextfreie Grammatik darstellbare Sprache:{anbncn|n Î IN}.läßt sich mit einer solchen Grammatik generieren:S::=abTcEine Ableitung mit dieser Grammatik sieht wie folgt aus:
T::=AbTc | e
bA::=Ab
aA::=aa
S
® abTc
® abAbTcc
® abAbAbTccc
® abAbAbAbTcccc
® abAbAbAbAbTccccc
® abAbAbAbAbccccc
® abAAbbAbAbccccc
® abAAbAbbAbccccc
® abAAAbbbAbccccc
® abAAAbbAbbccccc
® abAAAbAbbbccccc
® abAAAAbbbbccccc
® aAbAAAbbbbccccc
® aAAbAAbbbbccccc
® aAAAbAbbbbccccc
® aAAAAbbbbbccccc
® aaAAAbbbbbccccc
® aaaAAbbbbbccccc
® aaaaAbbbbbccccc
® aaaaabbbbbccccc
Als Preis dafür, daß man sich nicht auf kontextfreie Grammatiken
beschränkt, kann nicht immer leicht und eindeutig erkannt werden, ob
ein bestimmter vorgegebener Satz mit dieser Grammatik erzeugt werden
kann.
Grammatiken und Bäume
Im letzten Kapitel haben wir uns ausführlich mit Bäumen
beschäftigt. Eine Grammatik stellt in naheliegender Weise nicht nur
ein Beschreibung einer Sprache dar, sondern jede Generierung eines
Satzes dieser Sprache entspricht einem Baum, dem Ableitungsbaum.
Die Knoten des Baumes
sind mit Terminal- und Nichtterminalzeichen markiert, wobei Blätter
mit Terminalzeichen markiert sind. Die Kinder eines Knotens sind die
Knoten, die mit der rechten Seite einer Regelanwendung markiert sind.
Liest man die Blätter eines solchen Baumes von links nach rechts, so
ergibt sich der generierte Satz.
Gegenüber unserer bisherigen Darstellung der Ableitung eines Wortes
mit den Regeln einer Grammatik, ist die Reihenfolge, in der die Regeln
angewendet werden in der Baumdarstellung nicht mehr ersichtlich. Daher
spricht man häufiger auch vom Syntaxbaum des Satzes.
Beispiel:
Die Ableitungen der Sätze unserer ersten Grammatik haben folgende Baumdarstellung:
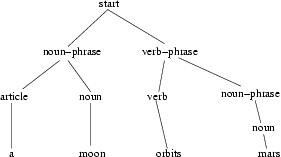
Aufgabe 21
Betrachten Sie die einfache Grammatik für arithmetische
Ausdrücke aus dem letzen Abschnitt. Zeichnen Sie einen Syntaxbaum für den
Audruck 1+1+2*20.
4.1.2 Erweiterte Backus-Naur-Form
Die Ausdrucksmöglichkeit einer kontextfreien Grammatik ist auf wenige
Konstrukte beschränkt. Das macht das Konzept einfach. Im Kontext von
Programmiersprachen gibt es häufig sprachliche Konstrukte, wie die
mehrfache Wiederholung oder eine Liste von bestimmten Teilen, die zwar
mit einer kontextfreien Grammatik darstellbar ist, für die aber
spezielles zusätzliche Ausdrucksmittel in der Grammatik eingeführt
werden. In den nächsten Abschnitten werden wir diese Erweiterungen
kennenlernen, allerdings werden wir in unseren Algorithmen für Sprachen
und Grammatiken diese Erweiterungen nicht berücksichtigen.
Alternativen
Wenn es für ein Nichtterminalzeichen mehrere Regeln gibt, so werden
diese Regeln zu einer Regel umgestaltet. Die unterschiedlichen rechten
Seiten werden dann durch einen vertikalen
Strich | gestrennt.
Durch diese Darstellung verliert man leider den direkten Zusammenhang
zwischen den Regeln und einen Ableitungsbaum.
Beispiel:
Die Regeln unserer ersten Grammatik können damit wie folgt geschrieben werden:start ::= noun-phrase verb-phrasenoun-phrase ::= noun | article nounverb-phrase ::= verb noun-phrasenoun ::= planet | moon | mars | deimos | phoebusverb ::= orbits | isarticle ::= a
Gruppierung
Bestimmte Teile der rechten Seite einer Grammatik können durch
Klammern gruppiert werden. In diesen Klammern können wieder durch
einen vertikalen Strich getrennte
Alternativen stehen.
Beispiel:
Die einfache Grammatik für arithmetische Ausdrücke läßt sich damit ohne das Nichtterminalzeichen op schreiben:start ::= exprexpr ::= integer | integer (+ | - | * | /) exprinteger ::= digit | digit integerdigit ::= 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Wiederholungen
Ein typische Konstrukt in Programmiersprachen ist, daß bestimmte
Kontrukte wiederholt werdn können. So stehen
z.B. in Java im Rumpf einer
Methode mehrere Anweisungen. Solche Sprachkonstrukte lassen sich mit einer
kontextfreien Grammatik ausdrücken.
Beispiel:
Eine Zahl besteht aus einer Folge von n Ziffern (n > 0). Dieses läßt sich durch folgende Regel ausdrücken:Zahl ::= Ziffer Zahl | Ziffer
1 bis n-fach
Im obigen Beispiel handelt es sich um eine 1 bis n-fache
Wiederholung des Zeichens Ziffer. Hierzu gibt es eine
abkürzende Schreibweise. Dem zu wiederholenden Teil wird das
Zeichen + nachgestellt.
Beispiel:
Obige Regel für das Nichtterminal Zahl läßt sich mit dieser abkürzenden Schreibweise schreiben als:Zahl ::= Ziffer+
0 bis n-fach
Soll ein Teil in einer Wiederholung auch keinmal vorkommen, so wird
statt des Zeichens + das Zeichen * genommen.
Beispiel:
Folgende Regel drückt aus, daß ein Ausdruck eine durch Operatoren getrennte Liste von Zahlen ist.expr ::= Zahl | (Op Zahl)*
Option
Ein weiterer Spezialfall der Wiederholung ist die, in der der
entsprechende Teil keinmal oder einmal vorkommen darf, d.h. der Teil
ist optional. Optionale Teile werden in der erweiterten Form in eckige
Klammern gesetzt.
4.2 Parser
Grammatiken geben an, wie Sätze einer Sprache gebildet werden
können. In der Informatik interessiert der umgekehrte Fall. Ein Satz
ist vorgegeben und es soll geprüft werden, ob dieser Satz mit einer
bestimmten Grammatik erzeugt werden kann. Ein Javaübersetzer
prüft z.B. ob ein vorgegebenes Programm syntaktisch zur durch
die Javagrammatik beschriebenen Sprache gehört.
Hierzu ist ein Prüfalgorithmus anzugeben, der testet, ob die Grammatik
einen bestimmten Satz generieren kann. Ein solches Programm
wird Parser genannt. Ein Parser6 zerteilt einen Satz in seine syntaktischen
Bestandteile.
4.2.1 Parsstrategien
Man kann unterschiedliche Algorithmen benutzen, um zu testen, daß ein
zu der Sprache einer Grammatik gehört. Eine Strategie geht primär von
der Grammatik aus, die andere betrachten eher den zu prüfenden Satz.
Rekursiv absteigend
Eine einfache Idee zum Schreiben eines Parsers ist es, einfach
nacheinander auszuprobieren, ob die Regelanwendung nach und nach einen
Satz bilden kann. Hierzu startet man mit dem Startsymbol und wendet
nacheinander die Regeln an. Dabei wendet man immer eine Regel auf das
linkeste Nichtterminalzeichen an, so lange, bis der Satzanfang
abgelitten wurde, oder aber ein falscher Satzanfang abgelitten
wurde. Im letzteren Fall hat man offensichtlich bei einer Regel die
falsche Alternative gewählt. Man ist in eine Sackgasse geraten.
Nun geht man in seiner Ableitung zurück bis
zu der letzten Regelanwendung, an der eine andere Alternative hätte
gewählt werden können. Man spricht dann von backtracking; auf
deutsch kann man treffend von Zurückverfolgen sprechen.
Auf diese Weise gelangt man entweder zu einer Ableitung des Satzes,
oder stellt irgendwann fest, daß man alle Alternativen ausprobiert hat
und immer in eine Sackgasse geraten ist. Dann ist der Satz nicht in
der Sprache.
Diese Strategie ist eine Suche. Es wird systematisch aus allen
möglichen Ableitungen in der Grammatik nach der Ableitung gesucht, die
den gewünschten Satz findet.
Beispiel:Alternativ könnte man diese Strategie auch symetrisch nicht von links sondern von der rechten Seite an ausführen, also immer eine Regel für das rechtestes Nichtterminalsymbol anwenden.
Wir suchen mit dieser Strategie die Ableitung des Satzes a moon orbits mars in dem Sonnensystembeispiel. Sackgassen sind durch einen Punkt · markiert.
(0) start (1) aus 0 ® noun-phrase verb-phrase (2a) aus 1 ® noun verb-phrase (2a3a) aus 2a ® planet verb-phrase · (2a3b) aus 2a ® moon verb-phrase · (2a3c) aus 2a ® mars verb-phrase · (2a3d) aus 2a ® deimos verb-phrase · (2a3e) aus 2a ® phobus verb-phrase · (2b) aus 1 ® article noun verb-phrase (3) aus 2b ® a noun verb-phrase (4a) aus 3 ® a planet verb-phrase · (4b) aus 3 ® a moon verb-phrase (5) aus 4b ® a moon verb noun-phrase (6) aus 5 ® a moon orbits noun-phrase (7) aus 6 ® a moon orbits noun (8a) aus 7 ® a moon orbits planet · (8b) aus 7 ® a moon orbits moon · (8c) aus 7 ® a moon orbits mars
Linksrekursion
Die Strategie des rekursiven Abstiegs auf der linken Seite
funktioniert für eine bestimmte Art von Regeln nicht. Dieses sind
Regeln, die in einer Alternative als erstes Symbol wieder das
Nichtterminalsymbol stehen haben, das auch auf der linken Seite
steht. Solche Regeln heißen linksrekursiv. Unsere Strategie terminiert
in diesen Fall nicht.
Beispiel:Es läßt sich also nicht für alle Grammatiken mit dem Verfahren des rekursiven Abstiegs entscheiden, ob ein Satz mit der Grammatik erzeugt werden kann; aber es ist möglich, eine Grammatik mit linksrekursiven Regeln so umzuschreiben, daß sie die gleiche Sprache generiert, jedoch nicht mehr linksrekursiv ist. Hierzu gibt es ein einfaches Schema:
Gegeben sei eine Grammatik mit einer linksrekursiven Regel:expr::=expr+zahl | zahlDer Versuch den Satzzahl+zahlmit einem links rekursiv absteigenden Parser abzuleiten, führt zu einem nicht terminierenden rekursiven Abstieg. Wir gelangen nie in eine Sackgasse:
Eine Regel nach dem Schema:
A ::= A rest | alt2ist zu ersetzen durch die zwei Regeln:
A::= alt2 Rwobei R ein neues Nichtterminalsymbol ist.
R::= rest R | e
Linkseindeutigkeit
Die rekursiv absteigende Strategie hat einen weiteren Nachteil. Wenn
sie streng schematisch angewendet wird, führt sie dazu, daß bestimmte
Prüfungen mehrfach durchgeführt werden. Diese mehrfache Ausführung
kann sich bei wiederholter Regelanwendung multipizieren und zu einem
sehr ineffizienten Parser führen. Grund dafür sind Regeln, die zwei
Alternativen mit gleichem Anfang haben:
S ::= AB | ABeide Alternativen für das Nichtterminalzeichen S starten mit dem Zeichen A. Für unseren Parser bedeutet das soweit: versuche nach der ersten Alternative zu parsen. Hierzu parse erst nach dem Symbol A. Das kann eine sehr komplexe Berechnung sein. Wenn sie gelingt, dann versuche anschließend weiter nach dem Symbol B zu parsen. Wenn das fehlschlägt, dann verwerfe die Regelalternative und versuche nach der zweiten Regelalternative zu parsen. Jetzt ist wieder nach dem Symbol A zu parsen, was wir bereits gemacht haben.
Regeln der obigen Art wirken sich auf unsere Parsstrategie ungünstig
aus. Wir können aber ein Schema angegeben, wie man solche Regeln aus
der Grammatik eleminiert, ohne die erzeugte Sprache zu ändern:
Regeln der Form
wobei T ein neues Nichtterminalzeichen ist.
S ::= AB | Asind zu ersetzen durch
S ::= AT
T ::= B | e
Vorausschau
Im letzten Abschnitt haben wir gesehen, wie wir die Grammatik
umschreiben können, so daß nach dem Zurücksetzen in unserem
Algorithmus es nicht vorkommt, bereits ausgeführte Regeln ein weiteres
Mal zu durchlaufen. Schöner noch wäre es, wenn wir auf das
Zurücksetzen ganz verzichten könnten. Dieses läßt sich allgemein nicht
erreichen, aber es gibt Grammatiken, in denen man durch Betrachtung
des nächsten zu parsenden Zeichens erkennen kann, welche der
Regelalternativen als einzige Alternative in betracht kommt. Hierzu
kann man für eine Grammatik für jedes Nichtterminalzeichen in jeder
Regelalternative berechnen, welche Terminalzeichen als linkestes
Zeichen in einem mit dieser Regel abgelittenen Satz auftreten
kann. Wenn die Regelalternativen disjunkte solche Menge des ersten
Zeichens haben, so ist eindeutig bei Betrachtung des ersten Zeichens
eines zu parsenden Satzes erkennbar, ob und mit welcher Alternative
dieser Satz nur parsbar sein kann.
Die gängigsten Parser benutzen diese Entscheidung, nach dem erstem
Zeichen. Diese Parser sind darauf angewiesen, daß die Menge der ersten
Zeichen der verschiedenen Regelalternativen disjunkt sind.
Der Vorteil an diesem Verfahren ist, daß die Token nach und nach von
links nach rechts stückweise konsumiert werden. Sie können durch einen
Datenstro, relisiert werden. Wurden sie einmal konsumiert, so werden
sie nicht mehr zum Parsen benötigt, weil es kein Zurücksetzen gibt.
Schieben und Reduzieren
Der rekursiv absteigende Parser geht vom Startsymbol aus und versucht
durch Regelanwendung den in Frage stehenden Satz abzuleiten.
Eine andere Strategie ist die des Schiebens-und-Reduzierens
(shift-reduce). Diese
geht vom im Frage stehenden Satz aus und versucht die Regeln rückwärts
anzuwenden, bis das Startsymbol erreicht wurde. Hierzu wird der Satz
von links nach rechts (oder symmetrisch von rechts nach links)
betrachtet und versucht, rechte Seiten von Regeln zu finden und durch
ihre linke Seite zu ersetzen. Dazu benötigt man einen Marker, der angibt, bis
zu welchen Teil man den Satz betrachtet. Wenn links des Markers keine
linke Seite einer Regel steht, so wird der Marker ein Zeichen weiter
nach rechts verschoben.
Wir werden im Laufe dieser Vorlesung diese Parserstrategie nicht
weiter verfolgen.
Beispiel:
Wir leiten im folgenden unserer allseits bekannten Beispielsatz aus dem Sonnensystem durch Schieben und Reduzieren ab. Als Marker benutzen wir einen Punkt.
| . a moon orbits mars | ||
| (shift) | ® | a . moon orbits mars |
| (reduce) | ® | article . moon orbits mars |
| (shift) | ® | article moon . orbits mars |
| (reduce) | ® | article noun . orbits mars |
| (reduce) | ® | noun-phrase . orbits mars |
| (shift) | ® | noun-phrase orbits . mars |
| (reduce) | ® | noun-phrase verb . mars |
| (shift) | ® | noun-phrase verb mars . |
| (reduce) | ® | noun-phrase verb noun . |
| (reduce) | ® | noun-phrase verb noun-phrase . |
| (reduce) | ® | noun-phrase verb-phrase . |
| (reduce) | ® | start. |
4.3 Handgeschriebene Parser
Genug der Theorie. Wir kennen jetzt Grammatiken und zwei Strategien,
um für einen Satz zu entscheiden, ob er mit einer Grammatik generiert
werden kann. In diesem Abschnitt wollen wir unsere theoretischen
Erkenntnisse in ein Programm praktisch umsetzen. Wir werden hierzu
einen rekursiv absteigenden Parser entwickeln.
4.3.1 Basisklassen der Parserbibliothek
Wir werden eine Bibliothek entwerfen, mit der Parser einer beliebigen Grammatik
konstruiert werden können. Parser werden dabei Objekte sein, insbesondere mit
einer Methode zum Parsen. Entwerfen wir also zunächst eine Schnittstelle, die
einen Parser beschreibt. Die Schnittstelle für Parser soll genau eine Methode
haben, die Methode parse. Sie bekommt ein Argument, die Liste der
Token, die zu parsen sind. Ein Parser erzeugt ein Ergebnis. Das Ergebnis kann
von beliebigen Typen sein: so gibt es Parser, die einen Baum als Ergebnis
produzieren, oder Parser, die nur als einen bool'schen Wert angeben, ob der
Parsevorgang erfolgreich war. Um diesem Rechnung zu tragen, lassen wir in der
Schnittstelle Parser den Ergebnistyp zunächst variabel. Wir erhalten
folgende generische Schnittstelle:
Parser
package name.panitz.parser;
import java.util.List;
public interface Parser<a> {
ParseResult<a> parse(List<Token> ts);
}
Für einen beliebigen aber festen Typen a können wir Parser
implementieren: so ist der Typ Parser<String> ein Parser, der
ein Stringobjekt als Ergebnis liefert.
Wir haben in der obigen Definition der Parserschnittstelle einen
Typ Token vorgesehen. Auch für diesen sehen wir eine Schnittstelle
vor:
Token
package name.panitz.parser;
public interface Token {}
Die Schnittstelle ist leer. Sie hat keine Eigenschaften.
Der Einfachheit
haben wir als einen Strom von Token eine Liste von Token verwenden.
Schließlich haben wir einen Typ ParseResult<a> in der
Parserschnittstelle vorgesehen. Das Ergebnis des Parsevorgangs eines Parser
des Typs Parser<a> ist vom Typ a. Es reicht aber nicht
aus, allein das Parseergebnis zurückzugeben. Wir müssen zusätzlich angeben,
welche Token durch den Parsvorgang konsumiert wurden. Daher haben wir einen
Typ ParseResult<a> vorgesehen, der aus zwei Teilen besteht:
- dem eigentlichen Ergebnis vom Typ a.
- der Liste der durch den Parsvorgang nicht konsumierten restlichen Token.
So läßt sich folgende Klasse für Parsergebnisse definieren:
ParseResult
package name.panitz.parser;
import java.util.List;
public class ParseResult<a> {
final private a result;
final private List<Token> remainingToken;
public ParseResult(a r,List<Token> toks){
result=r;remainingToken=toks;
}
public a getResult(){return result;}
public List<Token> getRemainingToken(){return remainingToken;}
public boolean failed(){return result==null;}
}
Wir haben für die zwei Teile eines Parsergebnisse jeweils
eine get-Methode definiert. Die Methode failed gibt
an ob es sich um einen erfolgreichen Parsvorgang gehandelt hat oder nicht.
Der Epsilon Parser
Wir können schon einen allerersten Parser schreiben, den Epsilonparser, der
kein Token der Eingabe konsumiert. Er endet immer erfolgreich.
Wir lassen ihm daher immer den Wert true als Ergebnis
zurückgeben. Kein Token der Eingabeliste wird konsumiert.
Epsilon
package name.panitz.parser;
import java.util.List;
public class Epsilon implements Parser<Boolean>{
public ParseResult<Boolean> parse(List<Token> ts){
return new ParseResult<Boolean>(true,ts);
}
}
4.3.2 Parser zum Erkennen von Token
Der allgemeine Rahmen für Parser ist nun abgesteckt. Jetzt können wir
schrittweise für komplexe Grammatiken Parser bauen. Der elementarste Parser
ist der, der prüft, ob ein bestimmtes Token als nächstes in der Eingabeliste
folgt. Hierzu ist eine Klasse, die Parser implementiert,
zu definieren, in der die Methode parse entsprechend implementiert
ist. In der Methode parse ist zunächst zu prüfen, ob die Tokenliste
nicht leer ist. Dann ist zu prüfen, ob das nächste Token ein bestimmtes Token,
nach dem der Parser sucht, gleicht. Im Erfolgsfall wird ein erfolgreiches
Ergebnis mit dem gefundenen Token erzeugt.
ParseToken
package name.panitz.parser;
import java.util.List;
public class ParseToken<a extends Token> implements Parser<a>{
final private a t;
public ParseToken(a _t){t=_t;}
public ParseResult<a> parse(List<Token> ts){
if (ts.isEmpty()) return new ParseResult<a>(null,ts);
if (ts.get(0).equals(t))
return new ParseResult<a>((a)ts.get(0),ts.subList(1,ts.size()));
return new ParseResult<a>(null,ts);
}
}
4.3.3 Parser zum Bilden der Sequenz zweier Parser
In einfachen Chomsky-Grammatiken gibt es nur zwei Arten wie für ein
Nichtterminalsymbol Regeln gebildet werden:
- durch die Sequenz mehrer Symbole auf der rechten Seite einer Regel.
- durch mehrere Regelalternativen.
Für diese beiden Bildungsprinzipien schreiben wir Parserobjekte, die aus
jeweils zwei Parser einen neuen Parser bilden.
In diesen Abschnitt machen wir das zunächst für die Sequenz zweier Parser.
Haben wir in der Grammatik eine Regel der Form:
A ::= B C
So können wir sie beim Schreiben eines Parser lesen als: Um den Parser für das
Nichtterminalsymbol A zu schreiben, schreibe die Parser für die
Symbole B und C und konstruiere mit diesen beiden den Parser
für das Symbol A durch den Sequenzparser aus den beiden Teilparsern.
Das Ergebnis einer Sequenz von zwei Parsern muß die beiden Parsergebnisse
irgendwie sinnvoll kombinieren. Hierzu sehen wir eine Klasse vor, die Paare
von zwei Objekten repräsentieren kann:
Pair
package name.panitz.parser;
public class Pair<a,b>{
final private a e1;
final private b e2;
public Pair(a x1,b x2){e1=x1;e2=x2;}
public a getE1(){return e1;}
public b getE2(){return e2;}
}
Die Sequenz zweier Parser kann jetzt als Parsergebnis ein Paar aus den beiden
Teilergebnissen haben. Wir implementieren den Parser, der die Sequenz zweier
Parser darstellt. Die zwei Teilparser werden dem Konstruktor übergeben:
Seq
package name.panitz.parser;
import java.util.List;
public class Seq<a,b> implements Parser<Pair<a,b>>{
final private Parser<a> p1;
final private Parser<b> p2;
public Seq(Parser< a> _p1,Parser< b> _p2){p1=_p1;p2=_p2;}
Die Methode parse wendet zunächst den ersten Parser auf die
Tokenliste an:
Seq
public ParseResult<Pair<a,b>> parse(List<Token> ts){
ParseResult<a> r1 = p1.parse(ts);
Sollte dieses schon mißglücken, so ist das Gesamtergebnis auch ein mißglückter
Parsversuch:
Seq
if (r1.failed()) return new ParseResult<Pair<a,b>>(null,ts);
Im erfolgreichen Fall sind die übrigen noch nicht konsumierten Token des
ersten Parses zu nehmen und der zweite Parser auf diese anzuwenden:
Seq
ParseResult<b> r2 = p2.parse(r1.getRemainingToken());
Sollte dieses schon mißglücken, so ist das Gesamtergebnis auch ein mißglückter
Parsversuch:
Seq
if (r2.failed()) return new ParseResult<Pair<a,b>>(null,ts);
Sind schließlich beide Parser erfolgreich gewesen ist ein erfolgreiches
Ergebnis als Paar der beiden Teilergebnisse zu bilden.
Seq
return new ParseResult<Pair<a,b>>
(new Pair<a,b>(r1.getResult(),r2.getResult())
,r2.getRemainingToken());
}
}
4.3.4 Parser zum Bilden der Alternative zweier Parser
Das zweite Bildungsprinzip, um für eine Grammatik einen Parser zu bauen, ist
die alternative Anwendung zweier bestehender Parser. In einer einfachen
Chomskygrammatik stellt sich dieses durch zwei Regelalternativen dar.
Haben wir in der Grammatik zwei Regeln der Form:
A ::= B
A ::= C
So können wir diese lesen als: um das Nichtterminal A zu parsen,
versuche den Parser für B, sollte dieses mißglücken versuche mit dem
Parser für C zu Parsen.
Entsprechend der Klasse Seq für die Sequenz von zwei Parsern
definieren wir die Klasse Alt für die Alternative aus zwei Parsern:
Alt
package name.panitz.parser;
import java.util.List;
import java.util.ArrayList;
public class Alt<a> implements Parser<a>{
final private Parser<a> p1;
final private Parser<a> p2;
public Alt(Parser<a> _p1,Parser<a> _p2){p1=_p1;p2=_p2;}
Zum Parsen der Alternative zweier Parser wird erst der erste der beiden ausprobiert:
Alt
public ParseResult<a> parse(List<Token> ts){
ParseResult<a> r1 = p1.parse(ts);
Sollte dieses mißglücken, so ist der zweite Parser auf derselben Tokenliste
anzuwenden, andernfalls ist das erfolgreiche Ergebnis des ersten Parses
zurückzugeben.
Alt
if (r1.failed()) return p2.parse(ts);
return r1;
}
}
4.3.5 Parser zum Verändern des Ergebnisses
Unsere kleine Parserbibliothek kann bisher drei Dinge:
- elementare Parser definieren, die bestimmte Token erkennen
- aus zwei Parsern die Sequenz bilden, die als Ergebnis das Paar der zwei Tailparses hat.
- aus zwei Parsern einen neuen Parser bilden, der einen der beiden Parser anzuwendet.
Oft will man etwas mit dem Ergebnis anstellen, nachdem ein Parser es
erfolgreich erkannt hat. Man möchte also auf das Ergebnis eine Funktion
anwenden. Hierzu definieren wir uns eine Schnittstelle, die zunächst einmal
beschreibt, wie Funktionsobjekte definiert sind.
Function
package name.panitz.parser;
public interface Function<a,b>{
b apply(a x);
}
Unsere letzte Klasse zum Bilden von Parsern, beschreibt einen Parser, der
zunächst einen vorgegebenen Parser auf die Tokenliste anwendet und
anschließend auf das erhaltene Ergebnis eine gegebene Funktion anwendet.
Map
package name.panitz.parser;
import java.util.List;
import java.util.ArrayList;
public class Map<a,b> implements Parser<b>{
final private Parser<a> p1;
final private Function<a,b> f;
public Map(Parser<a> _p1,Function<a,b> _f){p1=_p1;f=_f;}
Zum Parsen wird zunächst der gegebene Parser auf die Tokenliste angewendet:
Map
public ParseResult<b> parse(List<Token> ts){
ParseResult<a> r1 = p1.parse(ts);
Im Erfolgsfall wird ein neues Ergebnis gebaut, indem auf die Ergebiskomponente
die mitgegebene Funktion angewendet wird.
Map
if (r1.failed()) return new ParseResult<b>(null,ts);
return new ParseResult<b>
(f.apply(r1.getResult()),r1.getRemainingToken());
}
}
Unsere Parserbibliothek ist vollständig. In den nächsten Abschnitten sehen wir
Beispiele, wie sie zum Schreiben von Parsern benutzt werden kann.
4.3.6 Beispiel: arithmetische Ausdrücke
Als Beispiel betrachten wir eine Grammatik, die einfache arithmetische
Ausdrücke generiert.
Grammatik:
start ::= addExpr
addExpr ::= multExpraddOp addExpr | multExpr
multExpr ::= zahl multOp multExpr | zahl
multOp ::= * | /
addOp ::= + | -
Token
In unserer obigen Grammatik gibt es 5 verschiedene Token. Die vier Operatoren
und Zahlen. Für Zahlen können wir eine einfache Tokenklasse definieren, die
diese beschreibt.
Zahl
package name.panitz.parser;
public class Zahl implements Token{
final public int i;
public Zahl(int _i){i=_i;}
public boolean equals(Object o){return o instanceof Zahl;}
}
Die vier Operatoren können wir als Aufzählung realisieren:
OpToken
package name.panitz.parser;
public enum OpToken implements Token{
add,sub,mult,div;
Jeder Operator entspricht einer zweistelligen Funktion. Auch dieses können wir
mit Hilfe einer Schnittstelle ausdrücken:
BinFunction
package name.panitz.parser;
public interface BinFunction<a,b,c>{
c apply(a x,b y);
}
Die Operatoren sollen spezielle zweistellige Funktionen auf ganzen Zahlen
sein:
IntOp
package name.panitz.parser;
public interface IntOp
extends BinFunction<Integer,Integer,Integer>{}
Nun können wir in der Aufzählungsklasse der Operatortoken noch eine Methode
vorsehen, die zu dem entsprechenden Operator die entsprechende Funktion als
Ergebnis zurückgibt:
OpToken
public IntOp getFunction(){
switch (this){
case div : return new IntOp(){
public Integer apply(Integer x,Integer y){return x/y;}};
case mult : return new IntOp(){
public Integer apply(Integer x,Integer y){return x*y;}};
case add : return new IntOp(){
public Integer apply(Integer x,Integer y){return x+y;}};
default : return new IntOp(){
public Integer apply(Integer x,Integer y){return x-y;}};
}
}
}
AuswertungsParser
Wir schreiben einen ersten Parser, der für einen arithmetischen Ausdruck
seinen ausgewerteten Wert als Ergenis hat. Für jedes Symbol der Klasse
schreiben wir einen Parser, der eine ganze Zahl als Ergebnis hat.
Wir fangen mit den Terminalsymbolen an. Zunächst der Parser für Zahlen. Hier
handelt ich sich um den Tokenparser für das Token Zahl, auf den die
Funktion, die die eigentliche Zahl extrahiert angewendet wird.
ZahlEval
package name.panitz.parser;
import java.util.List;
public class ZahlEval implements Parser<Integer>{
public ParseResult<Integer> parse(List<Token> ts){
return new Map<Zahl,Integer>
(new ParseToken<Zahl>(new Zahl(0))
,new Function<Zahl,Integer>(){
public Integer apply(Zahl z){return z.i;}}
).parse(ts);
}
}
Als nächstes kümmern wir uns um die Operatoren. In einem Funktionsobjekt
kapseln wir die Funktion, die für ein Operatortoken die entsprechende
zweistellige Funktion extrahiert:
GetIntOp
package name.panitz.parser;
import java.util.List;
public class GetIntOp implements Function<OpToken,IntOp>{
public IntOp apply(OpToken t){
return t.getFunction();
}
}
Der Parser für Punktrechnungsoperatoren besteht aus der Alternative der beiden
Tokenparser mit anschließender Extraktion der binären Funktion:
MultOpEval
package name.panitz.parser;
import java.util.List;
public class MultOpEval implements Parser<IntOp>{
public ParseResult<IntOp> parse(List<Token> ts){
return new Map<OpToken,IntOp>
(new Alt<OpToken>
(new ParseToken<OpToken>(OpToken.mult)
,new ParseToken<OpToken>(OpToken.div))
,new GetIntOp()).parse(ts);
}
}
Analog funktioniert der Parser für die Strichrechnung:
AddOpEval
package name.panitz.parser;
import java.util.List;
public class AddOpEval implements Parser<IntOp>{
public ParseResult<IntOp> parse(List<Token> ts){
return new Map<OpToken,IntOp>
(new Alt<OpToken>
(new ParseToken<OpToken>(OpToken.add)
,new ParseToken<OpToken>(OpToken.sub))
,new GetIntOp()).parse(ts);
}
}
Als nächstes folgt der Parser für das
Nichtterminalsymbol multExpr.
multExpr ::= zahl multOp multExpr | zahl
Dieses ist entweder eine Sequenz
aus ZahlmultOp multExpr oder nur eine Zahl.
Die Sequenz hat als Ergebnistyp doppelt verschachtelte Paare des
Typs: Pair<Integer,Pair<IntOp,Integer>>. Aus diesen Typ
ist eine ganze Zahl zu bilden. Hierfür schreiben wir die
Klasse DoIntOp:
DoIntOp
package name.panitz.parser;
public class DoIntOp
implements Function<Pair<Integer,Pair<IntOp,Integer>>,Integer>{
public Integer apply(Pair<Integer,Pair<IntOp,Integer>> x){
return x.getE2().getE1().apply(x.getE1(),x.getE2().getE2());
}
}
Jetzt können wir entsprechend der Grammatik einen Parser für das
Nichtterminalsymbol multExpr schreiben:
MultExprEval
package name.panitz.parser;
import java.util.List;
public class MultExprEval implements Parser<Integer>{
public ParseResult<Integer> parse(List<Token> ts){
return
new Alt<Integer>
(new Map<Pair<Integer,Pair<IntOp,Integer>>,Integer>
(new Seq<Integer,Pair<IntOp,Integer>>
(new ZahlEval(),new Seq<IntOp,Integer>
(new MultOpEval(),new MultExprEval()))
,new DoIntOp()
)
,new ZahlEval()
).parse(ts);
}
}
Analog läßt sich der Parser für das
Nichtterminalsymbol addExpr schreiben:
addExpr ::= multExpraddOp addExpr | multExpr
AddExprEval
package name.panitz.parser;
import java.util.List;
public class AddExprEval implements Parser<Integer>{
public ParseResult<Integer> parse(List<Token> ts){
return
new Alt<Integer>
(new Map<Pair<Integer,Pair<IntOp,Integer>>,Integer>
(new Seq<Integer,Pair<IntOp,Integer>>
(new MultExprEval(),new Seq<IntOp,Integer>
(new AddOpEval(),new AddExprEval()))
,new DoIntOp()
)
,new MultExprEval()
).parse(ts);
}
}
Damit sind wir fertig. addExpr ist das Startsymbol der Grammatik.
EvalArith
package name.panitz.parser;
import java.util.List;
public class EvalArith implements Parser<Integer>{
Parser<Integer> startExpr = new AddExprEval();
public ParseResult<Integer> parse(List<Token> ts){
return startExpr.parse(ts);
}
}
Im folgenden eine kleine Testklasse für unseren ersten handgeschriebenen
Parser:
TestEvalArith
package name.panitz.parser;
import java.util.List;
import java.util.ArrayList;
public class TestEvalArith {
public static void main(String[] _){
List<Token> ts = new ArrayList<Token>();
ts.add(new Zahl(17));
ts.add(OpToken.mult);
ts.add(new Zahl(2));
ts.add(OpToken.add);
ts.add(new Zahl(8));
ParseResult<Integer> res = new EvalArith().parse(ts);
System.out.println(res.getResult());
System.out.println(res.getRemainingToken());
}
}
Aufbau eines Parsbaumes
In diesen Abschnitt schreiben wir einen zweiten Parser für die Grammatik der
arithmetischen Ausdrücke. Dieses mal liefert der Parser einen Baum als
Ergebnis.
Für jedes Symbol der Sprache schreiben wir wiesder genau eine Klasse. Die
Klasse unterscheiden sich von den Parserklassen des vorherigen Parser nur in
den Funktionsobjekten, die das Ergebnis berechnen.
ZahlTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
public class ZahlTree implements Parser<Tree<String>>{
public ParseResult<Tree<String>> parse(List<Token> ts){
return new Map<Zahl,Tree<String>>
(new ParseToken<Zahl>(new Zahl(0))
,new Function<Zahl,Tree<String>>(){
public Tree<String> apply(Zahl z){
return new Tree<String>(""+z.i);}}
).parse(ts);
}
}
OpTree
package name.panitz.parser;
import name.panitz.data.tree.*;
public interface OpTree
extends BinFunction<Tree<String>,Tree<String>,Tree<String>>{}
GetOpTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
import java.util.ArrayList;
public class GetOpTree implements Function<OpToken,OpTree>{
public OpTree apply(final OpToken t){
return
new OpTree(){
public Tree<String> apply(Tree<String>op1,Tree<String> op2){
List<Tree<String>> cs = new ArrayList<Tree<String>>();
cs.add(op1);
cs.add(op2);
return new Tree<String>(t.toString(),cs);
}
};
}
}
MultOpTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
public class MultOpTree implements Parser<OpTree>{
public ParseResult<OpTree> parse(List<Token> ts){
return new Map<OpToken,OpTree>
(new Alt<OpToken>
(new ParseToken<OpToken>(OpToken.mult)
,new ParseToken<OpToken>(OpToken.div))
,new GetOpTree()).parse(ts);
}
}
AddOpTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
public class AddOpTree implements Parser<OpTree>{
public ParseResult<OpTree> parse(List<Token> ts){
return new Map<OpToken,OpTree>
(new Alt<OpToken>
(new ParseToken<OpToken>(OpToken.add)
,new ParseToken<OpToken>(OpToken.sub))
,new GetOpTree()).parse(ts);
}
}
DoOpTree
package name.panitz.parser;
import name.panitz.data.tree.*;
public class DoOpTree
implements Function<Pair<Tree<String>,Pair<OpTree,Tree<String>>>
,Tree<String>> {
public Tree<String> apply
(Pair<Tree<String>,Pair<OpTree,Tree<String>>> x){
return x.getE2().getE1().apply(x.getE1(),x.getE2().getE2());
}
}
MultExprTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
public class MultExprTree implements Parser<Tree<String>>{
public ParseResult<Tree<String>> parse(List<Token> ts){
return
new Alt<Tree<String>>
(new Map<Pair<Tree<String>,Pair<OpTree,Tree<String>>>,Tree<String>>
(new Seq<Tree<String>,Pair<OpTree,Tree<String>>>
(new ZahlTree(),new Seq<OpTree,Tree<String>>
(new MultOpTree(),new MultExprTree()))
,new DoOpTree()
)
,new ZahlTree()
).parse(ts);
}
}
AddExprTree
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
public class AddExprTree implements Parser<Tree<String>>{
public ParseResult<Tree<String>> parse(List<Token> ts){
return
new Alt<Tree<String>>
(new Map<Pair<Tree<String>,Pair<OpTree,Tree<String>>>,Tree<String>>
(new Seq<Tree<String>,Pair<OpTree,Tree<String>>>
(new MultExprTree(),new Seq<OpTree,Tree<String>>
(new AddOpTree(),new AddExprTree()))
,new DoOpTree()
)
,new MultExprTree()
).parse(ts);
}
}
TreeArith
package name.panitz.parser;
import java.util.List;
import name.panitz.data.tree.*;
public class TreeArith implements Parser<Tree<String>>{
Parser<Tree<String>> startExpr = new AddExprTree();
public ParseResult<Tree<String>> parse(List<Token> ts){
return startExpr.parse(ts);
}
}
TestTreeArith
package name.panitz.parser;
import name.panitz.data.tree.*;
import java.util.List;
import java.util.ArrayList;
import javax.swing.*;
public class TestTreeArith {
public static void main(String[] _){
List<Token> ts = new ArrayList<Token>();
ts.add(new Zahl(17));
ts.add(OpToken.mult);
ts.add(new Zahl(2));
ts.add(OpToken.add);
ts.add(new Zahl(8));
ts.add(OpToken.mult);
ts.add(new Zahl(2));
ts.add(OpToken.div);
ts.add(new Zahl(1));
ts.add(OpToken.add);
ts.add(new Zahl(1));
ts.add(OpToken.sub);
ts.add(new Zahl(1));
ParseResult<Tree<String>> res = new TreeArith().parse(ts);
JFrame f = new JFrame();
f.getContentPane().add(new DisplayTree(res.getResult()));
f.pack();
f.setVisible(true);
System.out.println(res.getRemainingToken());
}
}
4.3.7 Tokenizer
Wir wollen wenigstens für die Grammatik der arithmetischen Ausdrücke
einen Tokenizer schreiben, so daß wir eine Anwendung schreiben können,
die eine Datei liest, deren Inhalt als arithmetischen Ausdruck parst
und in einer Bilddatei den Ableitungsbaum darstellt.
Wir sehen eine Klasse vor, die Tokenizerobjekte für die Token in
arithmethischen Ausdrücken darstellt:
ArithTokenizer
package name.panitz.parser;
import java.util.List;
import java.util.ArrayList;
import java.io.Reader;
import java.io.StringReader;
import java.io.IOException;
class ArithTokenizer {
Ein Tokenizer soll auf einen Eingabestrom des
Typs Reader operieren. Ein Feld soll das aktuelle aus diesem
Strom untersuchte Zeichen enthalten, und eine Liste die bisher
gefundenen Token:
ArithTokenizer
Reader reader; int next=0; List<Token> result = new ArrayList<Token>();
Wir sehen einen Konstruktor vor, der den Strom, aus dem gelesen wird
übergeben bekommt, und das erste Zeichen aus diesem Strom einliest:
ArithTokenizer
ArithTokenizer(Reader reader){
this.reader=reader;
try {
next= reader.read();
}catch (IOException _){}
}
Die entscheidene Methode tokenize liest nach und nach die
Zeichen aus dem Eingabestrom und erzeugt ja nach gelesenen Zeichen ein
Token für die Ergebnistokenliste:
ArithTokenizer
List<Token> tokenize() throws Exception{
try {
while (next>=0){
char c = (char)next;
switch (c){
Für Leerzeichen wird kein Token erzeugt:
ArithTokenizer
case '\u0020' : break;
case '\n' : break;
case '\t' : break;
Token, die aus einen Zeichen bestehen, erzeugen sobald das Zeichen
erkannt wurde ein Tokenobjekt für die Ausgabeliste:
ArithTokenizer
case '+' : result.add(OpToken.add) ; break;
case '-' : result.add(OpToken.sub) ; break;
case '*' : result.add(OpToken.mult); break;
case '/' : result.add(OpToken.div) ; break;
Wenn keines der obigen Zeichen gefunden wurde, kann es sich nur noch
um den Anfang einer Zahl, oder um eine fehlerhafte Eingabe handeln.
Wir unterscheiden, ob das Zeichen eine Ziffer darstellt, und versuchen
eine Zahl zu lesen, oder werfen eine Ausnahme:
ArithTokenizer
default : if (Character.isDigit(c)) {
result.add(getInt());
continue;
}else throw new Exception
("unexpected Token found: '"+c+"'");
}
Schließlich können wir den Strom um ein neues Zeichen bitten:
ArithTokenizer
next = reader.read();
}
}catch (IOException _){}
return result;
}
Zum Lesen von Zahlen holen wir solange Zeichen, wie noch Ziffern im
Eingabestrom zu finden sind und addieren diese auf.
ArithTokenizer
Token getInt() throws IOException {
int res=0;
while (next>=0 && Character.isDigit((char)next)){
res=res*10+next-48;
next = reader.read();
}
return new Zahl(res);
}
Schließlich schreiben wir uns zwei statische Methoden zur einfachen
Benutzung des Tokenizers.
ArithTokenizer
static List<Token> tokenize(String inp) throws Exception{
return tokenize(new StringReader(inp));
}
static List<Token> tokenize(Reader inp) throws Exception{
return new ArithTokenizer(inp).tokenize();
}
}
So lassen sich einfache Test in Jugs schnell durchführen:
sep@swe10:~/fh/prog2/examples> java Jugs
__ __ __ ____ ___ _________________________________________
|| || || || || ||__ Jugs: the interactive Java interpreter
|| ||__|| ||__|| __|| Copyright (c) 2003 Sven Eric Panitz
|| ___|| World Wide Web:
|| || http://www.tfh-berlin.de/~panitz
\\__// Version: February 2003 _________________________________________
>ArithTokenizer.tokenize("888+0009 *+-/ 9")
[888, add, 9, mult, add, sub, div, 9]
>ArithTokenizer.tokenize("888+0009 *uiu**+- 09")
java.lang.Exception: unexpected Token found: 'u'
>
Wir können die unterschiedlichsten Klassen aus diesem Skript für eine
kleine Anwendung zusammensetzen. Wir lesen eine Datei mit der
Endung .arith, in der ein arithmetischer Ausdruck steht. Die
Datei wird gelesen, die Tokenliste erzeugt und diese mit dem Parser
geparst. Der erzeugte Ableitungsbaum wird in einepng-Bilddatei geschrieben. Wir sehen ein paar praktische
statische Methoden zum Testen in Jugs und eine Hauptmethode vor:
ArithParsTreeBuilder
package name.panitz.parser;
import java.io.*;
import javax.imageio.ImageIO;
import javax.swing.*;
import name.panitz.data.tree.Tree;
import name.panitz.data.tree.DisplayTree;
import static name.panitz.data.tree.TreeToFile.treeToFile;
class ArithParsTreeBuilder{
public static void main(String [] args) throws Exception{
final String fileName = args[0];
writeParsTreeFile(new FileReader(fileName+".arith"),fileName);
}
static void writeParsTreeFile(Reader reader,String fileName)
throws Exception{
treeToFile(parsArith(reader),fileName);
}
public static Tree<String> parsArith(Reader reader)
throws Exception{
final ParseResult<Tree<String>> res
= new TreeArith().parse(ArithTokenizer.tokenize(reader));
return res.getResult();
}
public static DisplayTree parseAndShow(String inp)
throws Exception{
return new DisplayTree(parsArith(new StringReader(inp)));
}
public static void parseAndShowInFrame(String inp)
throws Exception{
JComponent c = ArithParsTreeBuilder.parseAndShow(inp);
JFrame f = new JFrame();
f.getContentPane().add(c);
f.pack();
f.setVisible(true);
}
}
Aufgabe 22
(2 Punkte) In dieser Aufgabe sollen Sie den Parser für
arithmetische Ausdrücke um geklammerte Ausdrücke erweitern.
Hierzu sei die Grammatik für die Regel multExpr wie folgt geändert:
multExpr ::= atomExpr multOp multExpr | atomExpr
atomExpr ::= (addExpr)|zahl
Hierzu sei die entsprechende zusätzliche Tokenaufzählung für die zwei
Klammersymbole gegeben:
Parentheses
package name.panitz.parser;
public enum Parentheses implements Token{lpar,rpar;}
Zusätzlich gegeben sei die die folgende Funktion:
DoParentheses
package name.panitz.parser;
public class DoParentheses
implements
Function<Pair<Parentheses,Pair<Integer,Parentheses>>,Integer>{
public Integer
apply(Pair<Parentheses,Pair<Integer,Parentheses>> x){
return x.getE2().getE1();
}
}
{\bf \alph{unteraufgabe})} Schreiben Sie eine Klasse AtomExprEval, die Parser<Integer> implementiert und der Regel für atomExpr entspricht.
{\bf \alph{unteraufgabe})} Ändern Sie die Klasse MultExprEval, so daß sie der geänderten Grammatikregel entspricht.
{\bf \alph{unteraufgabe})} Erweitern Sie die Klasse ArithTokenizer, so daß er auch die beiden Klammersymbole erkennt.
4.4 Parsergeneratoren
Im letzem Abschnitt haben wir gesehen, daß die Aufgabe einen Parser für
eine kontextfreie Grammatik zu schreiben eine mechanische Arbeit
ist. Nach bestimmten Regeln läßt sich eine Grammatik direkt in einen
Parser umsetzen. In unserem in Java geschriebenen Parser führte jede
Regel zu genau einer Methode.
Aus der Tatsache, daß einen Parser für eine Grammatik zu schreiben
eine mechanische Tätigkeit ist, folgt sehr schnell, daß man diese
gerne automatisiert durchführen möchte und in der Tat schon sehr bald
gab es Werkzeuge, die diese Aufgabe übernehmen konnten, sogenante
Parsergeneratoren. Heutzutage schreibt kaum ein Programmierer in einer
Sprache wie Java einen Parser von Hand, sondern läßt den Parser aus
der Definition der Grammatik generieren.
Der wohl am weitesten verbreitete Parsergenerator ist
Yacc[Joh75]. Wie man seinem Namen, der für yet
another compiler compiler steht, entnehmen kann, war dieses bei
weiten nicht der erste Parsergenerator. Yacc erzeugt traditionell
C-Code; es gibt aber mitlerweile auch Versionen, die Java-Code
generieren. Ein weitgehendst funktionsgleiches Programm zu Yacc
heißt Bison. Die lexikalische Analyse steht im im
Zusammenspiel mit Yacc und Bison jeweils auch ein Generatorprogramm
zur Verfügung, daß einen Tokenizer generiert. Dieses Programm
heißt lex.
Weitere modernere und auf Java zugeschnittene Parsergeneratoren
sind: yavacc, antlr und gentle[Gru01].
4.4.1 javacc
Wir wollen uns die Mühe machen, einen Parser mit einem Parsergenerator
zu beschreiben. Hierzu nehmen wir den
Parsergenerator javacc. Dieser Parsergenerator kommt mit zwei
Progammen:
- jjtree: Dieses Programm generiert Klassen, mit denen der Ableitungsbaum eines Parses dargestellt werden kann. Es nimmt als Eingabedatei eine Beschreibung der Grammatik. Diese Datei hat die Endung .jjt. Sie generiert Klassen für die Baumknoten. Zusätzlich generiert es eine Datei mit der Endung .jj. die im nächsten Schritt Eingabe für den eigentlichen Parsergenerator ist.
- javacc: Dieses Programm generiert eine Klasse für den eigentlichen Parser. Seine Eingabe ist eine Beschreibung der Grammatik in einer Datei mit Endung .jj. Sie generiert eine Klasse für den Parser und eine für die Token, die in der Grammatik spezifiziert werden. Zusätzlich werden Klassen zur Fehlerbehandlung generiert.
Eine wichtige Frage bei der Benutzung eines Parsergenerators ist, nach
welcher Strategie der generierte Parser vorgeht. Wenn es ein rekurisv
absteigender Parser ist, so dürfen wir keine Linksrekursion in der
Grammatik haben. Wenn der generierte Parser
kein backtracking hat, dann muß er mit Betrachtung des
aktuellen Tokens wissen, welche Regelalternative zu wählen ist. Die
Alternativen brauchen entsprechend disjunkte Startmengen. Bei
generierten Parsern mit der Strategie des Schieben und Reduzierens,
kann es sein, daß es zu sogenannten shift-reduce Konflikten
kommt, wenn nämlich bereits reduziert werden kann, aber auch nach
einem shift-Schritt reduziert werden kann.
Desweiteren ist wichtig, was für Konstrukte die Eingabegrammtik
zuläßt. Konfortable moderne Parsergeneratoren lassen heute die
erweiterte Backus-Naur-Form zur Beschreibung der Grammatik zu.
javacc generiert einen rekursiv absteigenden Parser
ohne backtracking. Es darf also keine linksrekursive Regel in
der Grammatik sein.
javacc integriert einen Tokenizer, d.h. mit der
Grammatik werden auch die Token definiert.
Aufgabe 23
Fügen Sie der Datei sms.jjt folgende Zeilen am
Anfang ein:
Beispiel:
Als erstes Beispiel wollen wir für unsere Sprache astronomischer Aussagen einen Parser generieren lassen. Hierzu schreiben wir eine Eingabegrammatikdatei mit den Namen sms.jjt.7.
Die Datei sms.jjt beginnt mit einer Definition der Klasse,
die den Parser enthalten soll. In unserem Beispiel soll die generierte
Klasse SMS heißen:
sms
PARSER_BEGIN(SMS)
public class SMS {
}
PARSER_END(SMS)
Anschließend lassen sich die Token der Sprache definieren. In unserem
Beispiel gibt es 8 Wörter. Wir können für javacc definieren,
daß Groß-und-Kleinschreibung für unsere Wörter irrelevant ist.
sms
TOKEN [IGNORE_CASE] :
{ <MOON: "moon">
| <MARS: "mars">
| <MERCURY: "mercury">
| <PHOEBUS: "phoebus">
| <DEIMOS: "deimos">
| <ORBITS: "orbits">
| <IS: "is">
| <A: "a">
}
Zusätzlich gibt es in javacc die Möglichkeit anzugeben, was
für Zwischenraum zwischen den Token stehen darf. In unserem Beispiel
wollen wir Leerzeichen, Tabularturzeichen und Zeilenendezeichen
zwischen den Wörtern als Trennung zulassen:
sms
SKIP :
{ " "
| "\t"
| "\n"
| "\r"
}
Und schließlich und endlich folgen die Regeln für die Grammatik:
sms
void start() : {}
{
nounPhrase() verbPhrase()
}
void nounPhrase() : {}
{
noun()|article() noun()
}
void noun() : {}
{ <MOON>|<MARS>|<MERCURY>|<PHOEBUS>|<DEIMOS>
}
void article() : {}
{<A>}
void verbPhrase() : {}
{
verb() nounPhrase()
}
void verb() : {}
{
<IS>|<ORBITS>
}
Aus dieser Datei sms.jj lassen sich jetzt mit dem
Programm jjtree Klassen für die Darstellung des
Ableitungsbaums generieren:
sep@swe10:~/fh/prog2/beispiele/javacc/sms> ls sms.jjt sep@swe10:~/fh/prog2/beispiele/javacc/sms> jjtree sms.jjt Java Compiler Compiler Version 2.1 (Tree Builder) Copyright (c) 1996-2001 Sun Microsystems, Inc. Copyright (c) 1997-2001 WebGain, Inc. (type "jjtree" with no arguments for help) Reading from file sms.jjt . . . File "Node.java" does not exist. Will create one. File "SimpleNode.java" does not exist. Will create one. Annotated grammar generated successfully in sms.jj sep@swe10:~/fh/prog2/beispiele/javacc/sms> ls JJTSMSState.java SMSTreeConstants.java sms.jj Node.java SimpleNode.java sms.jjt sep@swe10:~/fh/prog2/beispiele/javacc/sms>
Wie zu sehen ist, werden Klassen für Baumknoten
generiert (SimpleNode.java) und eine Eingabedatei für den
eigentlichen Parsergenerator (sms.jj). Jetzt können wir
diesen Parser generieren lassen:
sep@swe10:~/fh/prog2/beispiele/javacc/sms> javacc sms.jj Java Compiler Compiler Version 2.1 (Parser Generator) Copyright (c) 1996-2001 Sun Microsystems, Inc. Copyright (c) 1997-2001 WebGain, Inc. (type "javacc" with no arguments for help) Reading from file sms.jj . . . File "TokenMgrError.java" does not exist. Will create one. File "ParseException.java" does not exist. Will create one. File "Token.java" does not exist. Will create one. File "SimpleCharStream.java" does not exist. Will create one. Parser generated successfully. sep@swe10:~/fh/prog2/beispiele/javacc/sms> ls JJTSMSState.java SMSConstants.java SimpleNode.java sms.jjt Node.java SMSTokenManager.java Token.java ParseException.java SMSTreeConstants.java TokenMgrError.java SMS.java SimpleCharStream.java sms.jj sep@swe10:~/fh/prog2/beispiele/javacc/sms>
Die generierten Javaklassen lassen sich übersetzen:
sep@swe10:~/fh/prog2/beispiele/javacc/sms> javac *.java sep@swe10:~/fh/prog2/beispiele/javacc/sms> ls JJTSMSState.class SMSConstants.class SimpleNode.class JJTSMSState.java SMSConstants.java SimpleNode.java Node.class SMSTokenManager.class Token.class Node.java SMSTokenManager.java Token.java ParseException.class SMSTreeConstants.class TokenMgrError.class ParseException.java SMSTreeConstants.java TokenMgrError.java SMS.class SimpleCharStream.class sms.jj SMS.java SimpleCharStream.java sms.jjt sep@swe10:~/fh/prog2/beispiele/javacc/sms>
Bevor wir den Parser benutzen können, schauen wir uns die generierter
Parserdatei SMS.java in Auszügen einmal an:
/* Generated By:JJTree&JavaCC: Do not edit this line. SMS.java */
public class SMS/*bgen(jjtree)*/
implements SMSTreeConstants, SMSConstants {/*bgen(jjtree)*/
protected static JJTSMSState jjtree = new JJTSMSState();
static final public void start() throws ParseException {
/* bgen(jjtree) start */
SimpleNode jjtn000 = new SimpleNode(JJTSTART);
boolean jjtc000 = true;
jjtree.openNodeScope(jjtn000);
try {
nounPhrase();
verbPhrase();
} catch (Throwable jjte000) {
...
static final public void nounPhrase() throws ParseException {
/* bgen(jjtree) nounPhrase */
SimpleNode jjtn000 = new SimpleNode(JJTNOUNPHRASE);
boolean jjtc000 = true;
jjtree.openNodeScope(jjtn000);
try {
switch ((jj_ntk==-1)?jj_ntk():jj_ntk) {
case MOON:
case MARS:
case MERCURY:
case PHOEBUS:
kcase DEIMOS:
public SMS(java.io.InputStream stream) {
if (jj_initialized_once) {
....
Als erstes ist festzustellen, daß der generierte Parser kein gutes
objektorientiertes Design hat.
Es gibt für jede Regel der Grammatik eine Methode, allerdings sind
alle Methoden statisch.
Es gibt einen Konstruktor dem ein Objekt des
Typs java.io.InputStream, in dem die zu parsende Eingabe
übergeben wird.
Alle Methoden können im Fehlerfall
eine ParseException werfen, die angibt, wieso eine Eingabe
nicht geparst werden konnte.
Es gib ein Feld jjtreedes Typs JJTSMSState, in
welchem das Ergebnis des Parses gespeichert ist. Diese Klasse enthält
eine Methode Node rootNode(), mit der die Wurzel des
Ableitungsbaums erhalten werden kann.
Damit können wir eine Hauptmethode schreiben, in der wir den
generierten Parser aufrufen.
public class MainSMS {
public static void main(String args[]) throws ParseException {
SMS parser = new SMS(System.in);
parser.start();
((SimpleNode)parser.jjtree.rootNode()).dump("");
}
}
Als Eingabestrom definieren wir die Tastatureingabe. Wir benutzen die
Methode dump, um den Ableitungsbaum auf dem Bilschirm
auszugeben. Wir können nun das Hauptprgramm starten und mit der
Tastatur Sätze eingeben:
sep@swe10:~/fh/prog2/beispiele/javacc/sms> javac *.java
sep@swe10:~/fh/prog2/beispiele/javacc/sms> java MainSMS
a moon orbits mars
start
nounPhrase
article
noun
verbPhrase
verb
nounPhrase
noun
sep@swe10:~/fh/prog2/beispiele/javacc/sms> java MainSMS
mars is a red planet
Exception in thread "main" TokenMgrError:
Lexical error at line 1, column 11. Encountered: "r" (114), after : ""
at SMSTokenManager.getNextToken(SMSTokenManager.java:447)
at SMS.jj_ntk(SMS.java:298)
at SMS.noun(SMS.java:84)
at SMS.nounPhrase(SMS.java:50)
at SMS.verbPhrase(SMS.java:133)
at SMS.start(SMS.java:12)
at MainSMS.main(MainSMS.java:4)
sep@swe10:~/fh/prog2/beispiele/javacc/sms>
options {
MULTI=true;
STATIC=false;
}
Generieren Sie mit jjtree und javac den Parser
neu. Was hat sich geändert?
4.4.2 Parsen und moderne Programmierparadigmen
Wie an den Jahreszahlen der Literaturangaben zu sehen, sind Parser ein
sehr altes Geschäft. Die Grundlagen sind zu einer Zeit entwickelt
worden, in der es weder objektorientierte noch moderne funktionale
Programmiersprachen gab. Daher sind Parser- und vergleichbare
Algorithmen häufig in einer sehr prozeduralen Weise
formuliert. Modernere Entwicklungen der Progammiertechnik machen aber
auch vor Parsern nicht halt. Ein Kurs, der stärker das
objektorientierte Paradigma unterstützt findet sich
in [ACL02].
In der funktionalen Progammierung haben sich sogenannte
Parserkombinatoren durchgesetzt. Dieses sind Operatoren die zwei
Parser als die Sequenz der nacheinanderausführung kombinieren oder als
Alternativen kombinieren. Ein Parserkombinator stellt also eine
Funktion dar, die aus zwei Parsern einen neuen Parser als Ergebnis
hat. Da Parser selbst Funktionen sind, die einen Tokenstrom in einen
Parsbaum zerteilen, sind Parserkombinatoren Funktionen höherer
Ordnung: sie kombinieren zwei Funktionen zu einer neuen. Ein frühes
beeindruckendes Beispiel für Parserkombinatoren findet sich
in [FL89], in dem ausführlich eine Grammatik
für englischsprachige Sätze über das Sonnensystem modelliert und in
der Sprache Miranda[Tur85] implementiert ist.
Appendix A
Appendix A
Lösungen ausgewählter Aufgaben
A.1 Lösung der Punkteaufgabe zu Bäumen
In diesem Abschnitt werden einige Lösungen der dritten Punkteaufgabe
vorgestellt.
A.1.1 leaves
List leaves(): erzeugt eine Liste der Markierungen an den Blättern des Baumes.
Wir können die Methode leaves aus der
Methode flatten ableiten. Beide Methoden nehmen Elemente
eines Baumes und fügen diese in eine Ergebnisliste ein.
Tree
public List<a> leaves(){
//leere Liste für das Ergebnis
List<a> result = new ArrayList<a>();
//füge die Markierung dieses Knotens zur Ergebnisliste
//nur hinzu, wenn es ein Blatt ist
if (isLeaf()) result.add(mark());
//für jedes Kind
for (Tree<a> child:theChildren())
//erzeuge dessen Knotenliste und füge alle deren Blätter
//zum Ergebnis hinzu
result.addAll(child.leaves());
return result;
}
Alles, was zu ändern ist, ist eine Bedingung aufzustellen, wann ein
Knoten der Ergebnisliste hinzugefügt werden soll.
Bei flatten war das immer der Fall, bei leaves nur,
wenn es sich bei dem Baumknoten um ein Blatt
handelt.
Akkumulative Lösung
Wir haben uns bisher noch keine Gedanken um die Performanz unserer
Methoden gemacht. Wenn wir die die
Methoden flatten und leaves einmal genau betrachten,
so stellen
wir fest, daß jeder Aufruf der Methode eine neue Ergebnisliste
erzeugt. Das bedeutet, daß die
Methoden flatten und leaves durch die
rekursiven Aufrufe, soviel Listen erzeugt, wie Knoten im Baum sind. Mit dem
Aufruf der Methode addAll auf Listen, werden die Elemente
einer Liste in eine neue Liste eingetragen. Wir sind aber nur an einer
einzigen Liste interessiert, der endgültigen Ergebnisliste.
Es wäre also schön, wenn wir eine Methode flatten hätten,
die nicht eine neue Liste erzeugt, sondern eine bestehende Liste
benutzt, um dort weitere Elemente einzufügen. Wir können hierzu der
Methode einen Listenparameter geben, in dem die Ergebnisse zu sammeln
sind.
Tree
public List<a> flatten(List<a> result){
result.add(mark());
for (Tree<a> child:theChildren())
child.flatten(result);
return result;
}
Die eigentliche Methode flatten kann jetzt einmal das Objekt
für die Ergebnisliste erzeugen, und dann diese jeweils weitereichen,
um das Erzeugen neuer Listen und das umkopieren der Elemente von einer
Liste in eine andere zu verhindern.
Tree
public List<a> flattenAkk(){
return flatten(new ArrayList<a>());
}
Und entsprechend können wir die Methode leaves auch
umschreiben, so daß sie nicht für jeden rekursiven Aufruf ein neues
Listenobjekt erzeugt:
Tree
public List<a> leaves(List<a> result){
if (isLeaf()) result.add(mark());
for (Tree<a> child:theChildren())
child.leaves(result);
return result;
}
public List<a> leavesAkk(){
return leaves(new ArrayList<a>());
}
Dieses Prinzip, ein Ergebnis in einem Parameter nach und nach
zusammenzusammeln nennt man Akkumulation. Der Parameter, in
dem das Ergebnis jeweils hinzugefügt wird, ist der Akkumulator. Mit
Hilfe des Befehls time auf der Unix-Shell, läßt sich sogar
ungefähr messen,
daß die akkumulierende Methode schneller abgearbeitet wird.
Programmierung höherer Ordnung
Wir haben im letztem Abschnitt bereits beobachten können, daß die
Methoden flatten und leaves fast identischen Code
haben. Beide selektieren aus einem Baum bestimmte Baummarkierungen
heraus. Das einzige was sie unterscheidet, ist die Bedingung, die
steuert, ob eine Knotenmarkierung zu selektieren ist oder
nicht. Ansonsten haben wir Code verdoppelt.
Unser Bestreben ist stets eine Codeverdoppelung zu vermeiden, denn
verdoppelter Code ist auch doppelt zu pflegen und zu warten.
Das haben wir sogar schon festgestellt, als wir auf die akkumulative
Lösung der beiden Methoden gekommen sind. Da haben wir beide Methoden
geändert, um für sie die akkumulative Lösung einzuführen.
Wir
können eine Methode schreiben, die den gemeinsamen Code der beiden
Methoden enthält. Das
einzige, was die beiden Methoden unterscheidet ist eine
Bedingung. Diese Bedingung ist eine Prüfung auf die Baumknoten. Die
gemeinsame Methode muß diese Bedingung als Parameter übergeben
bekommen. Eine Prüfung ist eine Methode. Wir können in Java keine
Methoden direkt als Parameter übergeben, sondern nur Objekte. Wir
definieren daher eine Schnittstelle, die beschreibt, daß ein Objekt
eine Prüfmethoden enthält.
TreeCondition
package name.panitz.data.tree;
interface TreeCondition<a>{
boolean takeThis(Tree<a> o);
}
Mit dieser Schnittstelle sind wir jetzt in der Lage eine Bedingung auf
Baumknoten auszudrücken. Wir können damit eine allgemeine
Filtermethode schreiben, die Knoten mit einer bestimmten Bedingung aus
einem Baum selektiert. Die Methode filter ist die
Verallgemeinerung die Methoden leaves und flatten.
Wir verallgemeinern die akkumulative Lösung.
Tree
public List<a> filter(List<a> result,TreeCondition<a> c){
//wenn die Bedingung für den Knoten wahr ist, füge
//ihm dem Ergebnis hinzu
if (c.takeThis(this)) result.add(mark());
//für alle Kinder
for (Tree<a> child:theChildren())
//rufe den Filter mit gleicher Bedingung auf
child.filter(result,c);
return result;
}
Die akkumulative Methode kann noch wie gewohnt gekapselt werden:
Tree
public List<a> filter(TreeCondition<a> c){
return filter(new ArrayList<a>(),c);
}
Jetzt haben wir eine Methode geschrieben, die einmal durch einen Baum
läuft und Knoten aufgrund einer Bedingung in einer Ergebnisliste
sammelt. Wir können jetzt die
Methoden leaves und flatten über diese Methode ausdrücken:leaves ist ein Filter mit der Bedingung, daß die Baumknoten
ein Blatt ist. Wir erzeugen das Bedingungsobjekt als anonyme innere Klasse:
Tree
public List leavesFilter(){
return filter(
new TreeCondition<a>(){
public boolean takeThis(Tree<a> t){
return t.isLeaf();
}
});
}
flatten ist ein Filter mit der Bedingung die immer wahr
ist. Also erzeugen wir eine Baumbedingung, die
konstant true als Ergebnis liefert:
Tree
public List<a> flattenFilter(){
return filter(new TreeCondition<a>(){
public boolean takeThis(Tree<a> _){return true;}
});
}
Entsprechend können wir jetzt beliebige Bedingungen benutzen, um
Knoten aus dem Baum zu selektieren; z.B. alle Knoten
mit genau zwei Kindern:
Tree
public List<a> nodesWithTwoChildren(){
return filter(new TreeCondition<a>(){
public boolean takeThis(Tree<a> t){
return t.theChildren().size()==2;
}
});
}
Oder Knoten, die mit einem bestimmten Objekt markiert sind:
Tree
public List<a> nodesMarkedWith(final a o){
return filter(new TreeCondition<a>(){
public boolean takeThis(Tree<a> t){
return t.mark().equals(o);
}
});
}
Letztere Methode kann sogar genutzt werden, um zu entscheiden, ob ein
Objekt in einem Baum enthalten ist.
Tree
public boolean containsFilter(a o){
return !nodesMarkedWith(o).isEmpty();
}
Das in dieser Lösung vorgestellte Prinzip, daß quasi eine Methode als
Parameter an eine andere Methode übergeben wird,
heißt Programmierung höherer Ordnung. Java unterstützt dieses
Konzept nur rudimentär, weil zum Übergeben einer Methode als Parameter
erst ein Objekt erzeugt werden muß. In Sprachen wie C kann dieses
Programmierprinzip über Funktionszeiger realisiert werden. In Sprachen
der Lisp-Tradition ist die Übergabe von Methoden als
Parameter ein fundamentaler Bestandteil. Mit Hilfe der Programmierung
höherer Ordnung hat man ein sehr mächtiges Ausdrucksmittel.
A.1.2 show
String show(): erzeugt eine textuelle Darstellung des Baumes. Jeder Knoten soll eine eigene Zeile haben. Kinderknoten sollen gegenüber einem Elternknoten eingerückt sein.
Wir schreiben als erstes eine Methode, die einen Baum mit einer als
Parameter übergebenen Einrückung zeigt. Diese Einrückung wird für die
Kinder um zwei Zeichen verlängert:
Tree
public String show(String indent){
//zeige diesen Knoten mit Einrückung
String result = indent+mark();
//erhöhe die Einrückung
indent=indent+" ";
//für jedes Kind
for (Tree<a> child:theChildren())
//erzeuge neue Zeile und zeige Kind mit neuer Einrückung
result=result+"\n"+child.show(indent);
return result;
}
Die Wurzel eines Baumes zeigen wir ohne Einrückung. Wir kapseln die
obige Methode entsprechend:
Tree
public String show(){
return show("");
}
Akkumulative Lösung
Auch für die Methode show können wir eine akkumulative Lösung
schreiben. Der Grund, weshalb dieses sinnvoll ist, ist in der Technik
von der Stringumsetzung in Java versteckt. Der Übeltäter ist hierbei
der Operator + auf String. Dieser Operator hängt
nicht einen String an einen anderen String an,
sondern kopiert beide in einen neuen String. Jede Anwendung
des Operators + kopiert also String-Objekte; und wir
wenden den Operator oft an, um unser Ergebnis zu berechnen.
Java stellt eine Klasse zur Verfügung mit der String-Objekte
akkumuliert werden können, und Kopiervorgänge weitgehendst vermieden
werden: die Klasse StringBuffer.
Objekte der Klasse StringBuffer können mit der
Methode append weitere String-Objekte angehängt
werden. Sie wird benutzt, wenn ein String erst nach und nach
zusammengebaut wird.
Ähnlich wie bei der Akkumulation eines Listenergebnisses können wir
mit StringBuffer eine Zeichenkette akkumulieren. Hierzu geben
wir in einem Parameter einen StringBuffer als Akkumulator
mit. Wie im Listenfall mit der Methode add benutzen wir die
Methode append zum Aufsammeln der Ergebnisteile:
Tree
public StringBuffer show(String indent,StringBuffer result){
//zeige diesen Knoten mit Einrückung
result.append(indent);
result.append(mark().toString());
//erhöhe die Einrückung
indent=indent+" ";
//für jedes Kind
for (Tree<a> child:theChildren()){
//erzeuge neue Zeile und zeige Kind mit neuer Einrückung
result.append("\n");
child.show(indent,result);
}
return result;
}
Die kapselnde Methode, erzeugt einen
neuen StringBuffer, läßt diesen akkumulieren und gibt
schließlich den in ihm enthaltenen String als Ergebnis aus.
Tree
public String showAkk(){
return show("",new StringBuffer()).toString();
}
A.1.3 contains
boolean contains(a o): ist wahr, wenn eine Knotenmarkierung gleich dem Objekt o ist.
Wir haben im Zuge der Methode filter schon eine Lösung für
die Methode contains quasi umsonst bekommen. Diese Lösung hat
alle Knoten die das fragliche Objekt enthalten in einer Liste
gesammelt und gekuckt, ob die Liste leer ist oder nicht.
Dieses Prinzip wird manchmal auch unter dem Motto: representing
failure by a list of successes vorgestellt. Die Ergebnisliste
zeigt die Treffer an. contains falliert, wenn diese Liste
leer ist.
Der Nachteil
an dieser Lösung war, daß der gesammte Baum durchlaufen wurde, auch
wenn z.B. die Wurzel bereits der fragliche Knoten war.
Wir entwickeln nun eine Lösung, die einen Baum nur bis zum ersten
Auftreten des fraglichen Objektes durchläuft. Nur wenn das Objekt
nicht im Baum enthalten ist, wird der komplette Baum durchlaufen.
Tree
public boolean contains(a o){
//bin ich schon der gesuchte Knoten? Wenn ja ende mit erfolg
if (mark().equals(o)) return true;
//für jedes Kind
for (Tree<a> child:theChildren()){
//wenn es den Knoten enthält, beende mit erfolg
if (child.contains(o)) return true;
}
//keiner der Knoten enthielt das Objekt
return false;
}
A.1.4 maxDepth
int maxDepth(): gibt die Länge des längsten Pfades von der Wurzel zu einem Blatt an.
Die maximale Tiefe läßt sich relativ einfach finden. Jedes Kind wird
nach seiner maximalen Tiefe befragt und aus diesen die maximale Zahl
genommen. Schließlich wird diese um eins erhöht, für die Wurzel selbst.
Tree
public int maxDepth(){
//anfangstiefe
int result = 0;
//für jedes Kind
for (Tree<a> child:theChildren()){
//berechne seine maximale Tiefe
int n = child.maxDepth();
//ist sie höher als die bisher gefundene, dann nimm diese
if (n>result) result=n;
}
//erhöhe Ergebnis um eins für die Wurzel
return result+1;
}
A.1.5 getPath
List getPath(Object o): gibt die Markierungen auf dem Pfad von der Wurzel zu dem Knoten, der mit dem Objekt o markiert ist, zurück. Ergebnis ist eine leere Liste, wenn ein Objekt gleich o nicht existiert.naive Lösung
Fast alle Studenten haben eine Lösung entwickelt, in der die Aufgabe mit
Hilfe der Mehode contains realisiert wird. Jeder Knoten, der auf
dem Pfad zu dem fraglichen Objekt liegt, enthält diesen Knoten. Es
wird eine Ergebnisliste aufgebaut, die genau die Knoten enthält, deren
Bäume den fraglichen Knoten enthalten:
Tree
public List<a> getPathBad(a o){
List<a> result = new ArrayList<a>();
//wenn Du irgendwo das Objekt enthältst, liegst Du auf den Pfad
if (contains(o)) { result.add(mark());}
//für jedes Kind
for (Tree<a> child:theChildren()){
//füge den Pfad zum fraglichen Objekt hinzu
result.addAll(child.getPathBad(o));
}
return result;
}
Lösung höherer Ordnung mit Hilfe von filter
Die obige Lösung ist wieder von der Art: selektiere alle Knoten mit
einer bestimmten Eigenschaft aus den Baum. Die Eigenschaft ist keine
lokal den Knoten betreffende Eigenschaft, sondern die Tatsache, daß
der Teilbaum das Objekt enthält. Wir können also auch für diese
Aufgabe die Methode filter anwenden.
Tree
public List<a> getPathFilter(final a o){
return filter(
new TreeCondition<a>(){
public boolean takeThis(Tree<a> e){
return e.contains(o);
}
}
);
}
Spätestens jetzt merkt man, was für eine ausdrucksstarke Methode die
Methode filter durch ihren Parameter höherer Ordnung ist.
performantere Lösung
Beide obigen Lösungen waren schlecht, wenn wir ihr Laufzeitverhalten
betrachten. Stellen wir uns der Einfachheit halber einen zur Liste
entartetetn Baum mit n Knoten vor. Das einzige Blatt ist
der Knoten, zu dem der Pfad gesucht wird. Für jeden Knoten des Baumes
fragen wir, ob er das fragliche Objekt in seinem Teilbaum enthält, und
jedesmal durchlaufen wir dabei den Baum bis zu seinem Blatt, weil wir
die Methode contains aufrufen. Wir rufen
also n-Mal die Methode contains auf, die
jedesmal den Baum bis zum Blatt durchläuft. Wir durchlaufen
also n+(n-1)+(n-2)+...+(n-n)
Baumknoten, was nach der Summenformel [(n * (n+1))/2] ist.
Baumknoten, was nach der Summenformel [(n * (n+1))/2] ist.
Damit haben wir einen quadratischen Aufwand in Abhängigkeit von der
Tiefe des gesuchten Pfades. Quadratische Aufwände sind unbedingt zu
vermeiden, weil mit zunehmender Datengröße die Laufzeit eines
Algorithmus enorm schnell zunimmt.
Wir können mit einem kleinen Trick, auf die Benutzung der
Methode contains verzichten. Hierzu erinnern wir uns an das
Prinzip, einen Fehlschlag durch eine leere Liste zu
charakterisieren. Wir fragen einfach jedes Kind nach seinem Pfad zu
dem bewußten Objekt. Wenn diese Pfad leer ist, so enthält das Kind
diesen Knoten nicht. Sobald ein Kind uns einen nichtleeren Pfad gibt,
benutzen wir die überladene Methode add der
Listenschnittstelle, die uns erlaubt, ein Element an eine beliebige
Stelle einer Liste einzufügen.
Tree
public List<a> getPath(a o,List<a> result){
//bist Du selbst der Knoten,
//dann ende mit der einelementigen Liste
if (mark().equals(o)) { result.add(mark()); return result;}
for (Tree<a> child:theChildren()){
//berechne Pfad vom Kind zum Objekt
final List<a> path = child.getPath(o,result);
//Kind hat einen solchen Pfad
if (!path.isEmpty()){
//hänge Dich vorne dran
result.add(0,mark());
//und fertig
return result;
}
}
return result;
}
Da wir oben die akkumulative Methode geschrieben haben, benötigen wir
noch eine kapselnde Methode, in der die Ergebnisliste erzeugt wird:
public List<a> getPath(a o){
return getPath(o,new ArrayList<a>());
}
A.1.6 iterator
java.util.Iterator iterator(): erzeugt ein Iterator über alle Knotenmarkierungen des Baumes.
Wir brauchen einen Iterator, der alle Markierungen des Baumes
durchläuft. Wir können es und hier sehr einfach machen. Anstatt eine
eigene Iteratorklasse zu implementieren, die über die Knoten eines
Baumes läuft, können wir einfach unsere schon bestehende
Methode flatten benutzen, die die Elemente eines Baumes in
eine Liste steckt, um dann einfach den Iterator dieser Liste zu
benutzen:
Tree
public Iterator<a> iterator(){
return flatten().iterator();
}
A.1.7 sameStructure
boolean sameStructure(Tree other): soll genau dann wahr sein, wenn der Baum other die gleiche Struktur hat.
Zur Lösung durchlaufen wir die Struktur beider Bäume in gleicher
Weise, so lange bis, wir einen Unterschied in ihrer Struktur gefunden
haben. Falls wir, ohne auf eine Widerlegung der Strukturgleichheit zu
stoßen, beide Bäume komplett durchlaufen haben, dann haben beide Bäume
die gleiche Struktur.
Tree
public <b> boolean sameStructure(Tree<b> other){
//haben beide Bäume gleich viel Kinder.
if(this.theChildren().size()!=other.theChildren().size())
//wenn nein, dann sind sie nicht strukturgleich
return false;
//Iteriere über die Kinder beider Bäume
Iterator<Tree<a>> it1=this.theChildren().iterator();
Iterator<Tree<b>> it2=other.theChildren().iterator();
//solange es noch Kinder gibt
while (it1.hasNext()){
//hohle das nächste Kind beider Bäume
final Tree<a> thisChild = it1.next();
final Tree<b> otherChild =it2.next();
//sind diese nicht strukturgleich, dann breche ab
if (!thisChild.sameStructure(otherChild)) return false;
}
//die Strukturgleichheit wurde nie verletzt
return true;
}
Die einzige Schwierigkeit, die viele Studenten bei dieser Aufgabe
hatten, war gleichzeitig durch zwei Kinderlisten zu iterieren. Hierzu
bedarf es zweier Iteratoren, die aber in nur einer Schleife
gleichzeitig immer um eins weitergeschaltet werden.
A.1.8 equals
public boolean equals(Object other): soll genau dann wahr sein, wenn other ein Baum ist, der die gleiche Struktur und die gleichen Markierungen hat.
Wir können mit der obigen Lösung sehr schnell zu einer Lösung
kommen. Entweder wir kopieren die Methode der Strukturgleichheit und
fügen noch einen zusätzlichen Test ein, ob die Knotenmarkierungen
gleich sind:
if (!this.mark().equals(other.mark())) return false;
Oder aber, wir prüfen erst auf Strukturgleichheit und vergleichen dann
die Listen der Knoten beider Bäume auf Gleichheit.
Tree
public <b> boolean equals(Tree<b> other){
if (!this.sameStructure(other)) return false;
return this.flatten().equals(other.flatten());
}
Diese Lösung ist zwar schön kurz, aber durchläuft den Baum zweimal:
einmal, um die Struktur zu testen und ein zweites Mal um die
Markierungen auf Gleichheit zu testen.
In der Aufgabe war die Gleichheitsmethode mit dem Parameter des
Typs Object verlangt. Hierzu wird erst der Parameter
untersucht, ob er überhaupt ein Baum ist, und dann erst mit den
eigentlichen Vergleich begonnen:
Tree
public boolean equals(Object other){
if (! (other instanceof Tree)) return false;
Tree<?> o = (Tree<?>) other;
return this.equals(o);
}
}//end der Klasse Tree
Dies ist eine typische Implementierung für die Gleichheit. Es soll in
den meisten Fällen nur Gleiches mit Gleichen verglichen werden.
Appendix B
Appendix B
Hilfklasssen zu Swing
SwingWorker
Appendix C
package name.panitz.swing.threadTest;
import javax.swing.SwingUtilities;
/**
* This is the 3rd version of SwingWorker (also known as
* SwingWorker 3), an abstract class that you subclass to
* perform GUI-related work in a dedicated thread. For
* instructions on using this class, see:
*
* http://java.sun.com/docs/books/tutorial/uiswing/misc/threads.html
*
* Note that the API changed slightly in the 3rd version:
* You must now invoke start() on the SwingWorker after
* creating it.
*/
public abstract class SwingWorker {
private Object value; // see getValue(), setValue()
private Thread thread;
/**
* Class to maintain reference to current worker thread
* under separate synchronization control.
*/
private static class ThreadVar {
private Thread thread;
ThreadVar(Thread t) { thread = t; }
synchronized Thread get() { return thread; }
synchronized void clear() { thread = null; }
}
private ThreadVar threadVar;
/**
* Get the value produced by the worker thread, or null if it
* hasn't been constructed yet.
*/
protected synchronized Object getValue() {
return value;
}
/**
* Set the value produced by worker thread
*/
private synchronized void setValue(Object x) {
value = x;
}
/**
* Compute the value to be returned by the <code>get</code> method.
*/
public abstract Object construct();
/**
* Called on the event dispatching thread (not on the worker thread)
* after the <code>construct</code> method has returned.
*/
public void finished() {
}
/**
* A new method that interrupts the worker thread. Call this method
* to force the worker to stop what it's doing.
*/
public void interrupt() {
Thread t = threadVar.get();
if (t != null) {
t.interrupt();
}
threadVar.clear();
}
/**
* Return the value created by the <code>construct</code> method.
* Returns null if either the constructing thread or the current
* thread was interrupted before a value was produced.
*
* @return the value created by the <code>construct</code> method
*/
public Object get() {
while (true) {
Thread t = threadVar.get();
if (t == null) {
return getValue();
}
try {
t.join();
}
catch (InterruptedException e) {
Thread.currentThread().interrupt(); // propagate
return null;
}
}
}
/**
* Start a thread that will call the <code>construct</code> method
* and then exit.
*/
public SwingWorker() {
final Runnable doFinished = new Runnable() {
public void run() { finished(); }
};
Runnable doConstruct = new Runnable() {
public void run() {
try {
setValue(construct());
}
finally {
threadVar.clear();
}
SwingUtilities.invokeLater(doFinished);
}
};
Thread t = new Thread(doConstruct);
threadVar = new ThreadVar(t);
}
/**
* Start the worker thread.
*/
public void start() {
Thread t = threadVar.get();
if (t != null) {
t.start();
}
}
}
Appendix C
Beispielaufgaben
Appendix D
Referate
Studenten wird die Gelegenheit gegeben, statt der Übungsaufgaben ein
Referat auszuarbeiten und zu halten. Erwartet wird eine kurze
schriftliche Ausarbeitung mit einem kleine Beispiel und ein
halbstündiger Vortrag in der Übung.
Zu folgenden Themen sind im SS03 Referate gehalten worden:
D.1 JNI: Javas Schnittstelle zu C
Wie können Javaprogramme mit C-Programmen kommunizieren. Hierzu gibt
es JNI (java native interface).
D.2 Java 2D Grafik
In Java gibt es ein umfangreiches Paket zum Erzeugen und zeichnen
graphischer Objekte.
D.3 Java 3D Grafik
In Java gibt es ein umfangreiches Paket zum Erzeugen und zeichnen
animierter dreidimensionaler graphischer Objekte.
D.4 Java und Netzwerk
Wie greift man mit Java auf Netzwerkresourcen zu.
D.5 Java und Datenbanken
Wie greift man mit Java auf eine Datenbank zu.
Appendix E
Appendix E
Gesammelte Aufgaben
Aufgabe 0
Die Methode actionPerformed der
Schnittstelle ActionListener bekommt ein Objekt der
Klasse ActionEvent übergeben. In dieser gibt es eine
Methode getWhen, die den Zeitpunkt, zu dem das Ereignis aufgetreten
ist als eine Zahl kodiert zurückgibt. Mit dieser Zahl können Sie die
Klasse java.util.Date instanziieren, um ein Objekt zu bekommen, das
Datum und Uhrzeit enthält.
Schreiben Sie jetzt eine Unterklasse von JTB, so daß beim Drücken des
Knopfes, jetzt die aktuelle Uhrzeit im Textfeld erscheint.
Aufgabe 1
Schreiben Sie eine kleine Guianwendung mit einer Textfläche und drei
Knöpfen, die einen erweiterten Zähler darstellt:
- einen Knopf zum Erhöhen eines Zählers.
- einen Knopf zum Verringern des Zählers um 1.
- einen Knopf zum Zurücksetzen des Zählers auf 0.
Aufgabe 2
Schreiben Sie Ihr Programm eines Zählers mit drei Knöpfen jetzt so, daß sie
innere Klassen benutzen.
Aufgabe 3
(Punkteaufgabe 2 Punkte) Schreiben Sie eine
GUI-Komponente StrichKreis, die mit geraden Linien einen Kreis
entsprechend untenstehender Abbildung malt. Der Radius des Kreises
soll dabei dem Konstruktor der
Klasse StrichKreis als int-Wert
übergeben werden.
Testen Sie Ihre Klasse mit folgender Hauptmethode:
public static void main(String [] args) {
StrichKreis k = new StrichKreis(120);
JFrame f = new JFrame();
JPanel p = new JPanel();
p.add(new StrichKreis(120));
p.add(new StrichKreis(10));
p.add(new StrichKreis(60));
p.add(new StrichKreis(50));
p.add(new StrichKreis(70));
f.getContentPane().add(p);
f.pack();
f.setVisible(true);
}
Hinweis: In der Klasse java.lang.Math finden Sie Methoden
trigeometrischer Funktionen.
Insbesondere toRadians zum Umrechnen von Gardwinkel in Bogenmaß
sowie sin und cos.
Aufgabe 4
Erweitern Sie die Strichkreisklasse aus der letzten Aufgabe, so daß
jeder Strich in einer anderen Farbe gezeichnet wird.
Aufgabe 5
(2 Punkte)
Implementieren Sie eine Analoguhr. Das Ziffernblatt dieser Uhr können
Sie dabei mit den Methoden auf einem Graphics-Objekt zeichnen, oder
Sie können versuchen eine Bilddatei zu laden und das Ziffernblatt als Bild
bereitstellen. Als Anregung für ein Ziffernblatt können Sie sich das Bild
des
Ziffernblatts der handgefertigten Sekundenuhr (http://www.panitz.name/prog2/examples/images/wiebking.jpg) des Uhrmachers
G.Wiebking herunterladen.
Aufgabe 6
Schreiben Sie eine Animation, in der zwei Kreise sich bewegen. Die
Kreise sollen an den Rändern der Spielfläche abprallen und sie sollen
ihre Richtung ändern, wenn sie sich berühren.
Aufgabe 7
Schreiben Sie eine Animation, deren Verhalten über Mausklicks
beeinflussen können.
Aufgabe 8
Erzeugen Sie ein Baumobjekt, das einen Stammbaum Ihrer
Familie darstellt. Die Knoten und Blätter sind mit Namen markiert. Die
Wurzel ist mit Ihren Namen markiert.
Kinderknoten sind mit den leiblichen Eltern der
Person eines Knotens markiert.
Aufgabe 9
Testen Sie die in diesem Abschnitt entwickelten Methoden auf
Bäumen mit dem in der letzten Aufgabe erzeugten Baumobjekt.
Aufgabe 10
Punkteaufgabe (4 Punkte):
Für diese Aufgabe gibt es maximal 4 auf die Klausur anzurechnende Punkte. Abgabetermin: wird noch bekanntgegeben.
Für diese Aufgabe gibt es maximal 4 auf die Klausur anzurechnende Punkte. Abgabetermin: wird noch bekanntgegeben.
Schreiben Sie die folgenden weiteren Methoden für die
Klasse Tree. Schreiben Sie Tests für diese Methoden.
{\bf \alph{unteraufgabe})} List leaves(): erzeugt eine Liste der Markierungen an den Blättern des Baumes.
{\bf \alph{unteraufgabe})} String show(): erzeugt eine textuelle Darstellung des Baumes. Jeder Knoten soll eine eigene Zeile haben. Kinderknoten sollen gegenüber einem Elternknoten eingerückt sein.
Beispiel:
william
charles
elizabeth
phillip
diana
spencer
Tipp: Benutzen Sie eine Hilfsmethode
String showAux(String prefix),
die den String prefix vor den erzeugten Zeichenketten anhängt.
{\bf \alph{unteraufgabe})} boolean contains(a o): ist wahr, wenn eine Knotenmarkierung gleich dem Objekt o ist.
{\bf \alph{unteraufgabe})} int maxDepth(): gibt die Länge des längsten Pfades von der Wurzel zu einem Blatt an.
{\bf \alph{unteraufgabe})} List<a> getPath(a o): gibt die Markierungen auf dem Pfad von der Wurzel zu dem Knoten, der mit dem Objekt o markiert ist, zurück. Ergebnis ist eine leere Liste, wenn ein Objekt gleich o nicht existiert.
{\bf \alph{unteraufgabe})} java.util.Iterator<a> iterator(): erzeugt ein Iterator über alle Knotenmarkierungen des Baumes.
Tipp: Benutzen Sie bei der Umsetzung die Methode flatten.
{\bf \alph{unteraufgabe})} public boolean equals(Object other): soll genau dann wahr sein, wenn other ein Baum ist, der die gleiche Struktur und die gleichen Markierungen hat.
{\bf \alph{unteraufgabe})} <b>boolean sameStructure(Tree<a> other): soll genau dann wahr sein, wenn der Baum other die gleiche Struktur hat. Die Markierungen der Knoten können hingegen unterschiedlich sein.
String showAux(String prefix),
die den String prefix vor den erzeugten Zeichenketten anhängt.
{\bf \alph{unteraufgabe})} boolean contains(a o): ist wahr, wenn eine Knotenmarkierung gleich dem Objekt o ist.
{\bf \alph{unteraufgabe})} int maxDepth(): gibt die Länge des längsten Pfades von der Wurzel zu einem Blatt an.
{\bf \alph{unteraufgabe})} List<a> getPath(a o): gibt die Markierungen auf dem Pfad von der Wurzel zu dem Knoten, der mit dem Objekt o markiert ist, zurück. Ergebnis ist eine leere Liste, wenn ein Objekt gleich o nicht existiert.
{\bf \alph{unteraufgabe})} java.util.Iterator<a> iterator(): erzeugt ein Iterator über alle Knotenmarkierungen des Baumes.
Tipp: Benutzen Sie bei der Umsetzung die Methode flatten.
{\bf \alph{unteraufgabe})} public boolean equals(Object other): soll genau dann wahr sein, wenn other ein Baum ist, der die gleiche Struktur und die gleichen Markierungen hat.
{\bf \alph{unteraufgabe})} <b>boolean sameStructure(Tree<a> other): soll genau dann wahr sein, wenn der Baum other die gleiche Struktur hat. Die Markierungen der Knoten können hingegen unterschiedlich sein.
Aufgabe 11
Schreiben Sie eine Methode List<Tree<a>> siblings(),
die die Geschwister eines Knotens
als Liste ausgibt. In dieser Liste der Geschwister soll der Knoten
selbst nicht auftauchen.
Aufgabe 12
Schreiben Sie eine modifizierende
Methode
void deleteChildNode(int n),
die den n-ten Kindknoten löscht, und stattdessen die Kinder des n-ten Kindknotens als neue Kinder mit einhängt.
Beispiel:
Aufgabe 13
Überschreiben Sie die
Methoden addLeaf und deleteChildNode in
der Klasse BinTree, so daß sie nur eine Ausnahme werfen,
wenn die Durchführung der Modifikation dazu führen würde, daß das
Objekt, auf dem die Methode angewendet wird, anschließend kein
Binärbaum mehr wäre.
void deleteChildNode(int n),
die den n-ten Kindknoten löscht, und stattdessen die Kinder des n-ten Kindknotens als neue Kinder mit einhängt.
Beispiel:
a
/ \
/ \
b c
/ \ / \
d e f g
/|\
h i j
|
| wird durch deleteChildNode(1) zu: |
|
|
Aufgabe 14
Schreiben Sie analog zur Methode flatten in der
Klasse Tree eine Methode
List<a> postorder(), die die Knoten eines Baumes in Postordnung linearisiert.
List<a> postorder(), die die Knoten eines Baumes in Postordnung linearisiert.
Aufgabe 15
Rechnen Sie auf dem Papier ein Beispiel für die Arbeitsweise
der Methode military().
Aufgabe 16
Zeichnen Sie schrittweise die Baumstruktur, die im
Programm TestSearchTree aufgebaut wird.
Aufgabe 17
Erzeugen Sie ein Objekt des typs SearchTree und
fügen Sie nacheinander die folgenden Elemente ein:
"anna","berta","carla","dieter","erwin","florian","gustav"
Lassen Sie anschließend die maximale Tiefe des Baumes ausgeben.
"anna","berta","carla","dieter","erwin","florian","gustav"
Lassen Sie anschließend die maximale Tiefe des Baumes ausgeben.
Aufgabe 18
{\bf \alph{unteraufgabe})} Schreiben sie entsprechend die Methode:
static public SearchTree rotateLeft(SearchTree t)
{\bf \alph{unteraufgabe})}
Schreiben Sie in der Klasse BinTree die
entsprechende modifizierende Methode rotateLeft()
{\bf \alph{unteraufgabe})} Testen Sie die beiden Rotierungsmethoden. Testen Sie, ob die Tiefe der Kinder sich verändert und ob die Inordnung gleich bleibt. Testen Sie insbesondere auch einen Fall, in dem die NullPointerException abgefangen wird.
{\bf \alph{unteraufgabe})} Testen Sie die beiden Rotierungsmethoden. Testen Sie, ob die Tiefe der Kinder sich verändert und ob die Inordnung gleich bleibt. Testen Sie insbesondere auch einen Fall, in dem die NullPointerException abgefangen wird.
Aufgabe 19
Erweitern Sie die obige Grammatik so, daß sie mit ihr auch
geklammerte arithmetische Ausdrücke ableiten können. Hierfür gibt es
zwei neue Terminalsymbolde: ( und ).
Schreiben Sie
eine Ableitung für den Ausdruck: 1+(2*20)+1
Aufgabe 20
Betrachten Sie die einfache Grammatik für arithmetische
Ausdrücke aus dem letzen Abschnitt. Zeichnen Sie einen Syntaxbaum für den
Audruck 1+1+2*20.
Aufgabe 21
(2 Punkte) In dieser Aufgabe sollen Sie den Parser für
arithmetische Ausdrücke um geklammerte Ausdrücke erweitern.
Hierzu sei die Grammatik für die Regel multExpr wie folgt geändert:
multExpr ::= atomExpr multOp multExpr | atomExpr
atomExpr ::= (addExpr)|zahl
Hierzu sei die entsprechende zusätzliche Tokenaufzählung für die zwei
Klammersymbole gegeben:
Parentheses
package name.panitz.parser;
public enum Parentheses implements Token{lpar,rpar;}
Zusätzlich gegeben sei die die folgende Funktion:
DoParentheses
package name.panitz.parser;
public class DoParentheses
implements
Function<Pair<Parentheses,Pair<Integer,Parentheses>>,Integer>{
public Integer
apply(Pair<Parentheses,Pair<Integer,Parentheses>> x){
return x.getE2().getE1();
}
}
{\bf \alph{unteraufgabe})} Schreiben Sie eine Klasse AtomExprEval, die Parser<Integer> implementiert und der Regel für atomExpr entspricht.
{\bf \alph{unteraufgabe})} Ändern Sie die Klasse MultExprEval, so daß sie der geänderten Grammatikregel entspricht.
{\bf \alph{unteraufgabe})} Erweitern Sie die Klasse ArithTokenizer, so daß er auch die beiden Klammersymbole erkennt.
Aufgabe 22
Fügen Sie der Datei sms.jjt folgende Zeilen am
Anfang ein:
2.2 Fenster mit Textfläche
2.3 Fenster mit Textfläche und Knopf
2.4 Einfache graphische Komponente.
2.5 Kreis mit Durchmesserlinien.
2.6 Erste farbige Graphik.
2.7 Apfelmännchen.
2.8 Verschiedene Fontgrö ssen.
2.9 Transformationen auf Text in Graphics2D.
2.10 Überblick über einfache Komponenten.
2.11 Überblick über komplexere Komponenten.
2.12 Eine einfache Digitaluhr.
3.1 Modellierung von Bäumen mit einer Klasse.
3.2 Modellierung von Bäumen mittels einer Klassenhierarchie.
3.3 Baumdarstellung mit JTree.
3.4 Baum graphisch dargestellt mit DisplayTree.
3.5 Schematische Darstellung der Militärordnung.
3.6 Nicht balanzierter Baum.
3.7 Baum nach Rotierungsschritt.
3.8 Baum nach weiteren Rotierungsschritt.
4.1 Ableitungsbaum für a moon orbits mars.
4.2 Ableitungsbaum für mercury is a planet.
4.3 Ableitungsbaum für planet orbits a phoebus.
E.1 Kreis mit Durchmesserlinien.
options {
MULTI=true;
STATIC=false;
}
Generieren Sie mit jjtree und javac den Parser
neu. Was hat sich geändert?
Index
KlassenverzeichnisList of Figures
2.1 Ein erstes Fenster.2.2 Fenster mit Textfläche
2.3 Fenster mit Textfläche und Knopf
2.4 Einfache graphische Komponente.
2.5 Kreis mit Durchmesserlinien.
2.6 Erste farbige Graphik.
2.7 Apfelmännchen.
2.8 Verschiedene Fontgrö ssen.
2.9 Transformationen auf Text in Graphics2D.
2.10 Überblick über einfache Komponenten.
2.11 Überblick über komplexere Komponenten.
2.12 Eine einfache Digitaluhr.
3.1 Modellierung von Bäumen mit einer Klasse.
3.2 Modellierung von Bäumen mittels einer Klassenhierarchie.
3.3 Baumdarstellung mit JTree.
3.4 Baum graphisch dargestellt mit DisplayTree.
3.5 Schematische Darstellung der Militärordnung.
3.6 Nicht balanzierter Baum.
3.7 Baum nach Rotierungsschritt.
3.8 Baum nach weiteren Rotierungsschritt.
4.1 Ableitungsbaum für a moon orbits mars.
4.2 Ableitungsbaum für mercury is a planet.
4.3 Ableitungsbaum für planet orbits a phoebus.
E.1 Kreis mit Durchmesserlinien.
Bibliography
- [ACL02]
- César F. Acebal, Raúl Izquierdo Castanedo, and Juan M. Cueva Lovelle. Good design principles in a compiler university course. ACM SIGPLAN Notices, 37(4):62-73, 2002.
- [Cho56]
- Noam Chomsky. Three models for the description of language. IRE Transactions of Information Theory, 2:113-124, 1956.
- [CWH00]
- Mary Campione, Kathy Walrath, and Alison Huml. The Java Tutorial Third Edition. Addison-Wesley Publishing Company, 2000.
- [FL89]
- R. Frost and J. Launchbury. Constructing natural language interpreters in a lazy functional languages. The Computer Journal, 32(2):108-121, 1989.
- [GKS01]
- Ulrich Grude, Chritsoph Knabe, and Andreas Solymosi. Compilerbau. Skript zur Vorlesung, TFH Berlin, 2001. www.tfh-berlin.de/~grude/SkriptCompilerbau.pdf.
- [Gru01]
- Ulrich Grude. Einführung in gentle. Skript, TFH Berlin, 2001. www.tfh-berlin.de/~grude/SkriptGentle.pdf.
- [Joh75]
- Stephen C. Johnson. Yacc: Yet another compiler compiler. Technical Report 39, Bell Laboratories, 1975.
- [NB60]
- Peter Naur and J. Backus. Report on the algorithmic language ALGOL 60. Communications of the ACM, 3(5):299-314, may 1960.
- [Pan03]
- Sven Eric Panitz. Programmieren I. Skript zur Vorlesung, 2. revidierte Auflage, 2003. www.panitz.name/prog1/index.html.
- [Tur85]
- D. A. Turner. Miranda: A non-strict functional language with polymorphic types. In Functional Programming Languages and Computer Architecture, number 201 in Lecture Notes in Computer Science, pages 1-16. Springer, 1985.